Save to My DOJO
It’s a new year, and with it comes a new version of Altaro VM Backup! As mentioned in our launch blog post, we have just released version 7 of our flagship backup and recovery software for Hyper-V and VMware, which includes several enhancements and new features such as Boot from Backup and support for Windows Server 2016.
One feature however that we felt deserving of its own blog post was our new Augmented Inline Deduplication technology.
That’s what I’ll be talking about in this post today, with a highly detailed whitepaper to follow soon.
Quick Intro to Deduplication
Deduplication is a technology that is often synonymous with backup and DR software. For those that aren’t aware, the basic premise of deduplication is that no block of data is stored more than once. For example, if I have two copies of an application dataset on a file server, without deduplication there are two copies of that data contained within my backup repository as well.
I only need one copy of it to successfully recover the file, why should I store it twice in my backup repository?
This is where deduplication technology comes into place.
If you take a look at backup vendors throughout the industry, you’ll find deduplication to be a fairly common thing. However, with deduplication you’ll find that the details and the underlying mechanics are important and play a role as to how well the feature works. Before I get into how Altaro’s new Augmented Inline Deduplication technology works, let’s talk briefly about where we’ve been.
Reverse Delta
Pre-version 7, we used technology within our product stack called Reverse Delta, and while not specifically named deduplication, it served the same purpose. Every time a backup would occur, we would place the most recent data set in the most recent backup file, while compressing and deduping older data for that server into smaller delta files for historical backups. (Below)

While this worked well, there were some drawbacks. The main one being, we could only remove like copies of data on a per VM basis. So, let’s go back to our example above in that you have two copies of an application dataset, but instead of them being on the same file server, let’s say they’re on different servers that are both being backed up.
Our pre-version 7 reverse delta technology would have stored two copies of that data in the backup repository. This not only increased the amount of time needed to complete a backup, it consumed more storage.
This one of the key reasons for developing a better solution for our customers and Partners!
Augmented Inline Deduplication
We’re proud and happy to be able to bring to you this new Augmented Inline Deduplication technology built into Altaro VM Backup.
Not only is it quicker for backup operations, it is far more efficient for storage as well in that it will dedupe data across all your backed-up workloads. Whereas before with Reverse Delta, we were completing this process on a per VM basis, with our new Augmented Inline Deduplication feature, we’re storing backups in a central repository and using a hash database to keep track of the deduped blocks. (Below)
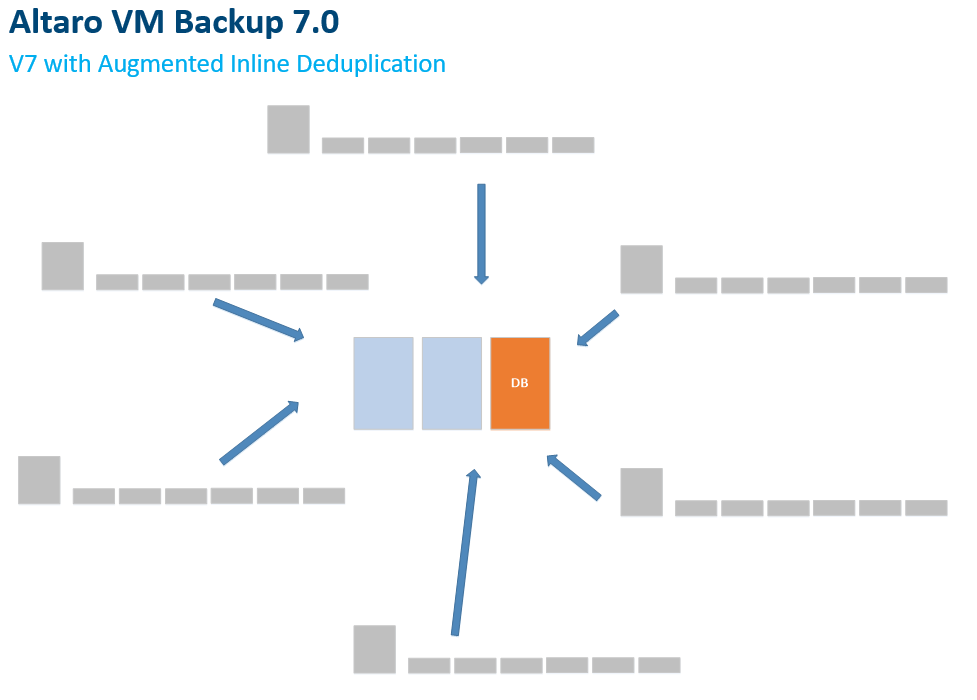
Not only does this method make it so you’re only storing one copy of each block, it also becomes more efficient with each new workload you add to the solution! Remember, there are similar files and data within the operating system of each server. If you have 10 Windows Server 2012 R2 machines, you’ll only have to backup 1 copy of the similar OS related files for all the protected VMs.
It’s also worth noting that this process occurs inline, and does NOT happen as a post process job. However, before I go too much further on that, maybe a small definition is in order to further show the differences between inline deduplication and post-process deduplication:
- Post-Process Deduplication – All data is backed up and sent to the backup repository. Once the job is complete, and new deduplication job occurs that looks at the data in the backup repository and removes like blocks.
- Inline Deduplication – Data is analyzed and compared to the backup repository prior to the backup process to ensure that identical blocks are not sent to the backup repository to begin with. This is the type of deduplication that our new Augmented Inline Deduplication technology is based off of.
If you compare these two types of deduplication technologies, it will quickly become apparent that post-process is the least efficient of the two.
Not only are you sending data over the wire that doesn’t need to be sent, you’re also having to parse and analyze the data after the fact as a second job to remove the like blocks. Talk about creating more work than what is needed!
As a result, using the inline method on our Augmented Inline Deduplication technology, Altaro VM Backup customers benefit from:
- Blazing fast backups
- The best backup storage savings in the industry

Wrap-Up
If you’re interested in seeing what our Augmented Inline Deduplication technology can do for your organization, feel free to download our full-featured 30-day trial. There is no obligation and it’s simple to setup and test within your environment. This will give you a good idea of how the solution will stack up in your environment and even give you a little bit of a feel for how much more efficiency you can gain from our new deduplication technology.
As always, if you have any questions or comments, feel free to submit them below, and don’t forget, we’ll be providing a highly detailed whitepaper on this feature soon for more detail!
Thanks for reading!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Andy Syrewicze

