Save to My DOJO
Table of contents
- What is Hyper-V CPU Compatibility Mode?
- Does Hyper-V’s CPU Compatibility Mode Impact the Performance of My Virtual Machine?
- How Do I Set CPU Compatibility Mode?
- A Primer on CPU Performance
- Enhanced Instruction Sets and Hyper-V Compatibility Mode
- Understanding Why CPU Compatibility Mode Isn’t a Problem
- What These Things Mean for Compatibility
- What These Things Do Not Mean for Compatibility
If there’s anything in the Hyper-V world that’s difficult to get good information on, it’s the CPU compatibility setting. Very little official documentation exists, and it only tells you why and how. I, for one, would like to know a bit more about the what. That will be the focus of this article.
What is Hyper-V CPU Compatibility Mode?
Hyper-V CPU compatibility mode is a per-virtual machine setting that allows Live Migration to a physical host running a different CPU model (but not manufacturer). It performs this feat by masking the CPU’s feature set to one that exists on all CPUs that are capable of running Hyper-V. In essence, it prevents the virtual machine from trying to use any advanced CPU instructions that may not be present on other hosts.
Does Hyper-V’s CPU Compatibility Mode Impact the Performance of My Virtual Machine?
If you want a simple and quick answer, then: probably not. The number of people that will be able to detect any difference at all will be very low. The number of people that will be impacted to the point that they need to stop using compatibility mode will be nearly non-existent. If you use a CPU benchmarking tool, then you will see a difference, and probably a marked one. If that’s the only way that you can detect a difference, then that difference does not matter.
I will have a much longer-winded explanation, but I wanted to get that out of the way first.
How Do I Set CPU Compatibility Mode?
Luke wrote a thorough article on setting Hyper-V’s CPU compatibility mode. You’ll find your answer there.
A Primer on CPU Performance
For most of us in the computer field, CPU design is a black art. It requires understanding of electrical engineering, a field that combines physics and logic. There’s no way you’ll build a processor if you can’t comprehend both how a NAND gate functions and why you’d want it to do that. It’s more than a little complicated. Therefore, most of us have settled on a few simple metrics to decide which CPUs are “better”. I’m going to do “better” than that.
CPU Clock Speed
Clock speed is typically the first thing that people generally want to know about a CPU. It’s a decent bellwether for its performance, although an inaccurate one.
A CPU is a binary device. Most people interpret that to mean that a CPU operates on zeros and ones. That’s conceptually accurate but physically untrue. A CPU interprets electrical signals above a specific voltage threshold as a “one”; anything below that threshold is a “zero”. Truthfully speaking, even that description is wrong. The silicon components inside a CPU will react one way when sufficient voltage is present and a different way in the absence of such voltage. To make that a bit simpler, if the result of an instruction is “zero”, then there’s little or no voltage. If the result of an instruction is “one”, then there is significantly more voltage.
Using low and high voltages, we solve the problem of how a CPU functions and produces results. The next problem that we have is how to keep those instructions and results from running into each other. It’s often said that “time is what keeps everything from happening at once”. That is precisely the purpose of the CPU clock. When you want to send an instruction, you ensure that the input line(s) have the necessary voltages at the start of a clock cycle. When you want to check the results, you check the output lines at the start of a clock cycle. It’s a bit more complicated than that, and current CPUs time off of more points than just the beginning of a clock cycle, but that’s the gist of it.
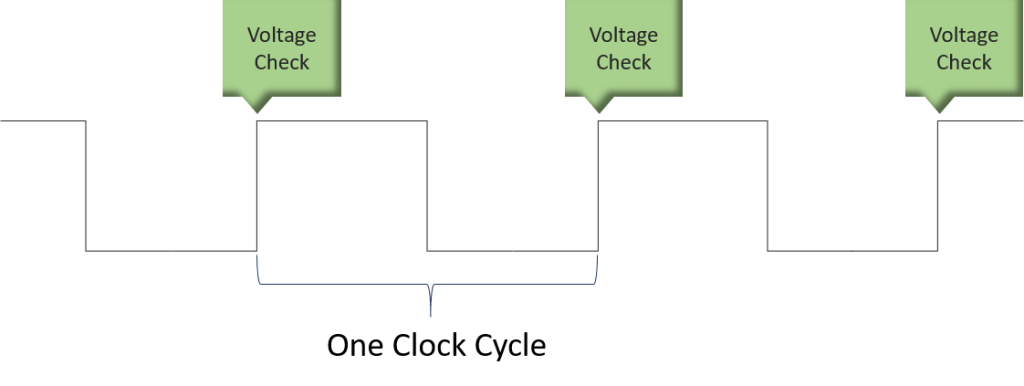
From this, we can conclude that increasing the clock speed gives us more opportunities to input instructions and read out results. That’s one way that performance has improved. As I said before, though, clock speed is not the most accurate predictor of performance.
Instructions per Cycle
The clock speed merely sets how often data can be put into or taken out of a CPU. It does not directly control how quickly a CPU operates. When a CPU “processes” an instruction, it’s really just electrons moving through logic gates. The clock speed can’t make any of that go any more quickly. It’s too easy to get bogged down in the particulars here, so we’ll just jump straight to the end: there is no guarantee that a CPU will be able to finish any given instruction in a clock cycle. That’s why overclockers don’t turn out earth-shattering results on modern CPUs.
That doesn’t mean that the clock speed isn’t relevant. It’s common knowledge that an Intel 386 performed more instructions per cycle than a Pentium 4. However, the 386 topped out at 33Mhz whereas the Pentium 4 started at over 1 GHz. No one would choose to use a 386 against a Pentium 4 when performance matters. However, when the clock speeds of two different chips are closer, internal efficiency trumps clock speed.
Instruction Sets
Truly exploring the depths of “internal efficiency” would take our little trip right down Black Arts Lane. I only have a 101-level education in electrical engineering so I certainly will not be a chauffeur on that trip. However, the discussion includes instructions sets, which is a very large subtopic that is directly related to the subject of interest in this article.
CPUs operate with two units: instructions and data. Data is always data, but if you’re a programmer, you probably use the term “code”. “Code” goes through an interpreter or a compiler which “decodes” it into an instruction. Every CPU that I’ve ever worked with understood several common instructions: PUSH, POP, JE, JNE, EQ, etc. (for the sake of accuracy, those are actually codes, too, but I figure it’s better than throwing a bunch of binary at you). All of these instructions appear in the 80×86 (often abbreviated as x86) and the AMD64 (often abbreviated as x64) instruction sets. If you haven’t figured it out by now, an instruction set is just a gathering of CPU instructions.
If you’ve been around for a while, you’ve probably at least heard the acronyms “CISC” and “RISC”. They’re largely marketing terms, but they have some technical merit. These acronyms stand for:
- CISC: Complete Instruction Set Computer
- RISC: Reduced Instruction Set Computer
In the abstract, a CISC system has all of the instructions available. A RISC system has only some of those instructions available. RISC is marketed as being faster than CISC, based on these principles:
- I can do a lot of adding and subtracting more quickly than you can do a little long division.
- With enough adding and substracting, I have nearly the same outcome as your long division.
- You don’t do that much long division anyway, so what good is all of that extra infrastructure to enable long division?
On the surface, the concepts are sound. In practice, it’s muddier. Maybe I can’t really add and subtract more quickly than you can perform long division. Maybe I can, but my results are so inaccurate that my work constantly needs to be redone. Maybe I need to do long division a lot more often than I thought. Also, there’s the ambiguity of it all. There’s really no such thing as a “complete” instruction set; we can always add more. Does a “CISC” 80386 become a “RISC” chip when the 80486 debuts with a larger instruction set? That’s why you don’t hear these terms anymore.
Enhanced Instruction Sets and Hyper-V Compatibility Mode
We’ve arrived at a convenient segue back to Hyper-V. We don’t think much about RISC vs. CISC, but that’s not the only instruction set variance in the world. Instructions sets grow because electrical engineers are clever types and they tend to come up with new tasks, quicker ways to do old tasks, and ways to combine existing tasks for more efficient results. They also have employers that need to compete with other employers that have their own electrical engineers doing the same thing. To achieve their goals, engineers add instructions. To achieve their goals, employers bundle the instructions into proprietary instruction sets. Even the core x86 and x64 instruction sets go through revisions.
When you Live Migrate a virtual machine to a new host, you’re moving active processes. The system already initialized those processes to a particular instruction set. Some applications implement logic to detect the available instruction set, but no one checks it on the fly. If that instruction set were to change, your Live Migration would quickly become very dead. CPU compatibility mode exists to address that problem.
The Technical Differences of Compatibility Mode
If you use a CPU utility, you can directly see the differences that compatibility mode makes. These screen shot sets were taken of the same virtual machine on AMD and Intel systems, first with compatibility mode off, then with compatibility mode on.
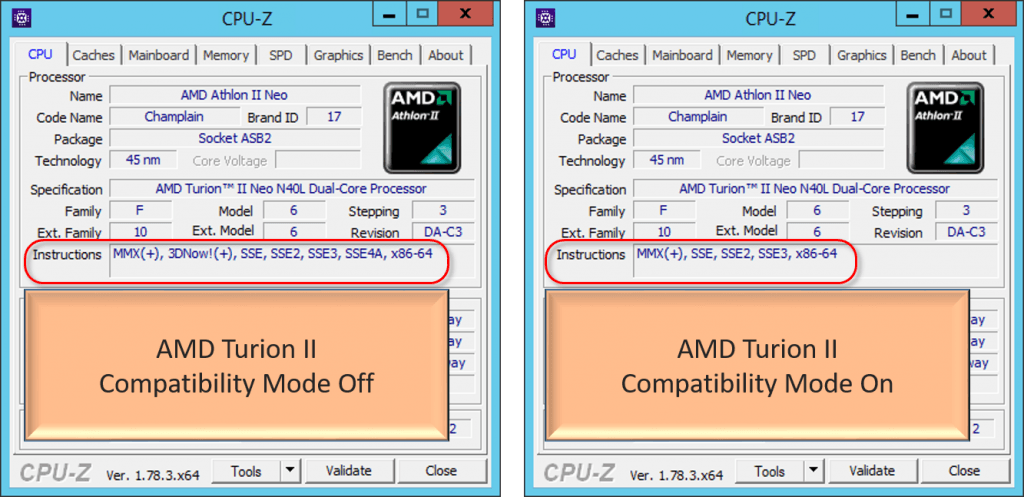
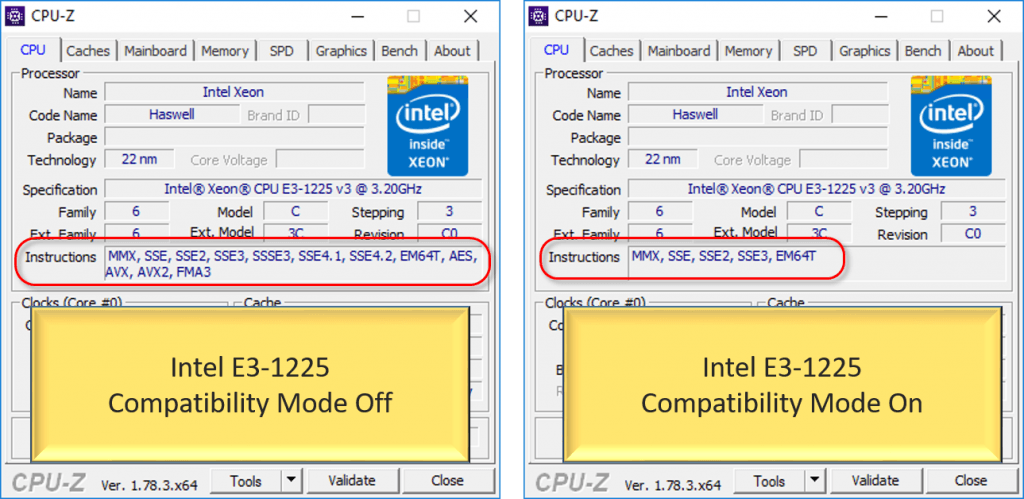
The first thing to notice is that the available instruction set list shrinks just by setting compatibility mode, but everything else stays the same.
The second thing to notice is that the instruction sets are always radically different between an AMD system and an Intel system. That’s why you can’t Live Migrate between the two even with compatibility mode on.
Understanding Why CPU Compatibility Mode Isn’t a Problem
I implied in an earlier article that good systems administrators learn about CPUs and machine instructions and code. This is along the same lines, although I’m going to take you a bit deeper, to a place that I have little expectation that many of you would go on your own. My goal is to help you understand why you don’t need to worry about CPU compatibility mode.
There are two generic types of software application developers/toolsets:
- Native/unmanaged: Native developers/toolsets work at a relatively low level. Their languages of choice will be assembler, C, C++, D, etc. The code that they write is built directly to machine instructions.
- Interpreted/managed: The remaining developers use languages and toolsets whose products pass through at least one intermediate system.Their languages of choice will be Java, C#, Javascript, PHP, etc. Those languages rely on external systems that are responsible for translating the code into machine instructions as needed, often on the fly (Just In Time, or “JIT”).
These divisions aren’t quite that rigid, but you get the general idea.
Native Code and CPU Compatibility
As a general rule, developing native code for enhanced CPU instruction sets is a conscious decision made twice. First, you must instruct your compiler to use these sets:
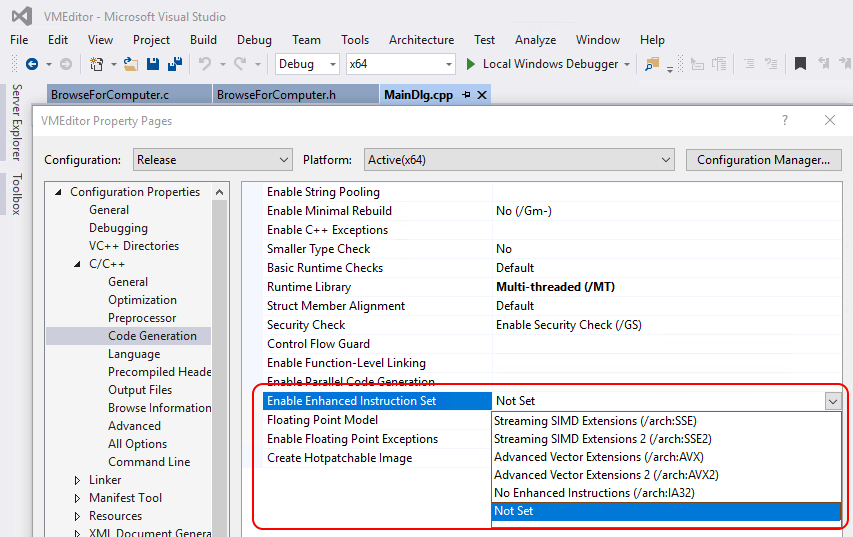
These are just the extensions that Visual Studio knows about. For anything more, you’re going to need some supporting files from the processor manufacturer. You might even need to select a compiler that has support built-in for those enhanced sets.
Second, you must specifically write code that calls on instructions from those sets. SSE code isn’t something that you just accidentally use.
Interpreted/Managed Code and CPU Compatibility
When you’re writing interpreted/managed code, you don’t (usually) get to decide anything about advanced CPU instructions. That’s because you don’t compile that kind of code to native machine instructions. Instead, a run-time engine will operate your code. In the case of scripting languages, that happens on the fly. For languages like Java and C#, they are first compiled (is that the right word for Java?) into some sort of intermediate format. Java becomes byte code; C# becomes Common Intermediate Language (CIL) and then byte code. They are executed by an interpreter.
It’s the interpreter that has the option of utilizing enhanced instruction sets. I don’t know if any of them can do that, but these interpreters all run on a wide range of hardware. That ensures that their developers are certainly verifying the existence of any enhancements that they intend to use.
What These Things Mean for Compatibility
What this all means is that even if you don’t know if CPU compatibility affects the application that you’re using, the software manufacturer should certainly know. If the app requires the .Net Framework, then I would not be concerned at all. If it’s native/unmanaged code, the manufacturer should have had the foresight to list any required enhanced CPU capabilities in their requirements documentation.
In the absence of all other clues, these extensions are generally built around boosting multimedia performance. Video and audio encoding and decoding operations feature prominently in these extensions. If your application isn’t doing anything like that, then the odds are very low that it needs these extensions.
What These Things Do Not Mean for Compatibility
No matter what, your CPU’s maximum clock speed will be made available to your virtual machines. There is no throttling, there is no cache limiting, there is nothing other than a reduction of the available CPU instruction sets. Virtual machine performance is unlikely to be impacted at all.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


8 thoughts on "Performance Impact of Hyper-V CPU Compatibility Mode"
It’s almost like you didn’t even RTFM and instead wrote a lengthy article…
Ramifications of using processor compatibility mode
It is difficult to quantify the overall performance effects of processor compatibility mode. The performance loss is primarily dependent on the workload running in the virtual machine. Some workloads will be completely unaffected, while others will show a noticeable difference. Software that heavily relies on hardware optimizations (such as encryption, compression, or intensive floating-point calculations) will be impacted the most.
The following example describes how AES encryption is affected by using processor compatibility mode, and there are many more. If you are concerned about the performance impact of processor compatibility mode, it is best to compare virtual machine workload performance with processor compatibility mode enabled and with it disabled.
Example: AES encryption
One example of an operation that is impacted by processor compatibility mode is AES encryption (a common form of encryption). Many new Intel and AMD processors include an ISA extension that accelerates AES by using hardware. Intel claims this optimization provides a 2-3 fold performance gain, with some implementations providing a 10-fold gain. (For more information, see Intel Advanced Encryption Standard Instructions.)
Applications that encrypt or decrypt a large amount of data benefit from this processor feature, so turning it off by enabling processor compatibility mode will impact the performance of these specific operations.
The article that you plagiarized specifically says that the workload’s dependency on CPU optimizations matters the most, just as this article does. Even the portion that you stole says that (“Applications that encrypt or decrypt a large amount of data…”). No one that depends on performing high volumes of AES encryption should try to solve the problem with a general-purpose virtualization cluster anyway. If you intended to throw some sort of slam-dunk refutation at me, you missed.
Hi Eric, thanks for that superb article. Really interesting stuff.
One question: I noticed that live migration of a hyper-v VM between “i7 6th gen” host1 and “i5 3rd gen” host2 fails with the “hardware limitations processor-specific error”…. I haven’t enabled CPU compatibility mode. Of course, if I enable this, it works without any issues.
Would I be right in assuming that migrating from i7 6th gen to i7 9th gen would have higher chances of not throwing that error when cpu compatibility mode is not enabled? I don’t have the hardware to test, just asking out of curiosity.
Thanks!!
I would think that the odds of moving over even one generation would be low. Sometimes crossing from the 1st to the 2nd version of the same chip causes it to block.
I just live-migrated several VMS from a 10 year old HP (Server 2012 R2) to a brand new Dell (Server 2019). I’ve been aware of the processor compatibility setting, but didn’t think to check it before kicking off the live migrations.
The live migrations were successful, VMs are running on new server. After migration, I noticed event log entries for each migration stating “The virtual machine ‘Vmxxx’ is not compatible is not compatible with the physical computer ‘VHxxx’
I’m confused. Have I made a terrible mistake? How did the migration complete successfully? If an application on the migrated VMs tries to access a now-nonexistent instruction set, will the VM crash? Alternatively, is the error message incorrect? Perhaps the old server has s subset of the new server’s instruction set, so no harm/no foul, just poorly worded event log entry?
If there was going to be a problem you likely would have encountered it already.
If you don’t mind, please share the entire event (id, source, text).