Save to My DOJO
Hardware failure presents the greatest drawback to consolidation on a hypervisor. Whereas one malfunctioning stick of RAM used to be a threat to one operating system, it can now bring down several virtual machines at once. Proper planning can mitigate and in some cases eliminate the effects of such a failure.
Planning Is Everything
Before you begin virtualizing, it’s best to have a disaster preparedness plan designed. If a physical host crashes, you’re going to be faced with the need to triage the recovery of multiple virtual machines. You may need to find contingency hardware for mission-critical servers. You may need to decide between spending your time attempting to repair failed hardware or acquiring emergency replacements. You may have to assess if it’s better to restore from backup or resurrect crashed virtual machines. You may have to completely erase drive arrays to clear out a dug-in virus. If you haven’t got a plan that considers these and other possibilities and contingencies, then you will waste precious time during the catastrophe to answer those questions. This planning is essentially a disaster recovery process and its mechanics have been fairly well standardized. Proper coverage of that topic greatly exceeds a single blog post, but the basic process is to assess your risks, establish your recovery goals, architect a solution that can achieve those goals, deploy the system, and test it. This discussion will highlight the major risks and some approaches to dealing with disaster in a Hyper-V environment.
The Anatomy of a Hyper-V Host Failure
Planning for the failure of a Hyper-V host requires an understanding of what happens when a host failure occurs. The primary impact is, of course, determined by the nature and severity of the failure. If a network adapter assigned as a virtual switch stops functioning, that might simply cause some virtual machines to lose their network connection. However, if a virtual machine was using it to connect to an iSCSI target, that VM might crash entirely. If a hard drive in the storage array for the virtual machines goes bad, it might cause all of the virtual machines to run at an intolerably slow pace while the array operates in degraded mode. If the performance impact is severe enough, some of them might even crash because they believe their hard drives are no longer responding.
Of course, most host failures are going to cause Hyper-V to simply crash. Causes might be transient, such as a driver failure, or permanent, such as the loss of a motherboard component. Dealing with those problems is not much different than the process for a non-virtualized system. Even in a worst-case scenario, Hyper-V itself is very easy to rebuild so there shouldn’t be much planning involved unless you are running it as a role inside Windows Server and the same installation is running other applications. The virtual machines are what require the most consideration. When Hyper-V crashes suddenly, all of its virtual machines that were powered on also crash. The biggest difference is that they almost always act as though they had simply lost power. So, even if the hypervisor reports that a driver error caused a kernel stop, all of its virtual machines will simply report that they were turned off unexpectedly. The Windows operating system can handle this situation very well, especially if it is using NTFS. Not all applications that might be installed on those Windows virtual machines are guaranteed to handle a crash quite so well. Your plan must involve recovering those applications.
Crashes in a Cluster
Multiple Hyper-V hosts can be installed into a Failover Cluster to add a layer of protection for your virtual machines. This scheme is a “high availability” mechanism and should not be confused with a “fault tolerant” mechanism. A “fault tolerant” system allows for a certain level of failure without causing any service interruption at all. Fault tolerance is possible within a Hyper-V system, but you’ll need to purchase third party solutions to achieve it. “High Availability” allows for a controlled move of virtual machines resources from one host to another with no downtime (LiveMigration) and it allows for the Failover Cluster technology to automatically move crashed virtual machines off of a crashed Hyper-V host to a live host and restart them there. It is important to understand that when a Hyper-V host crashes, all of its virtual machines crash too, even if the host is part of a cluster.
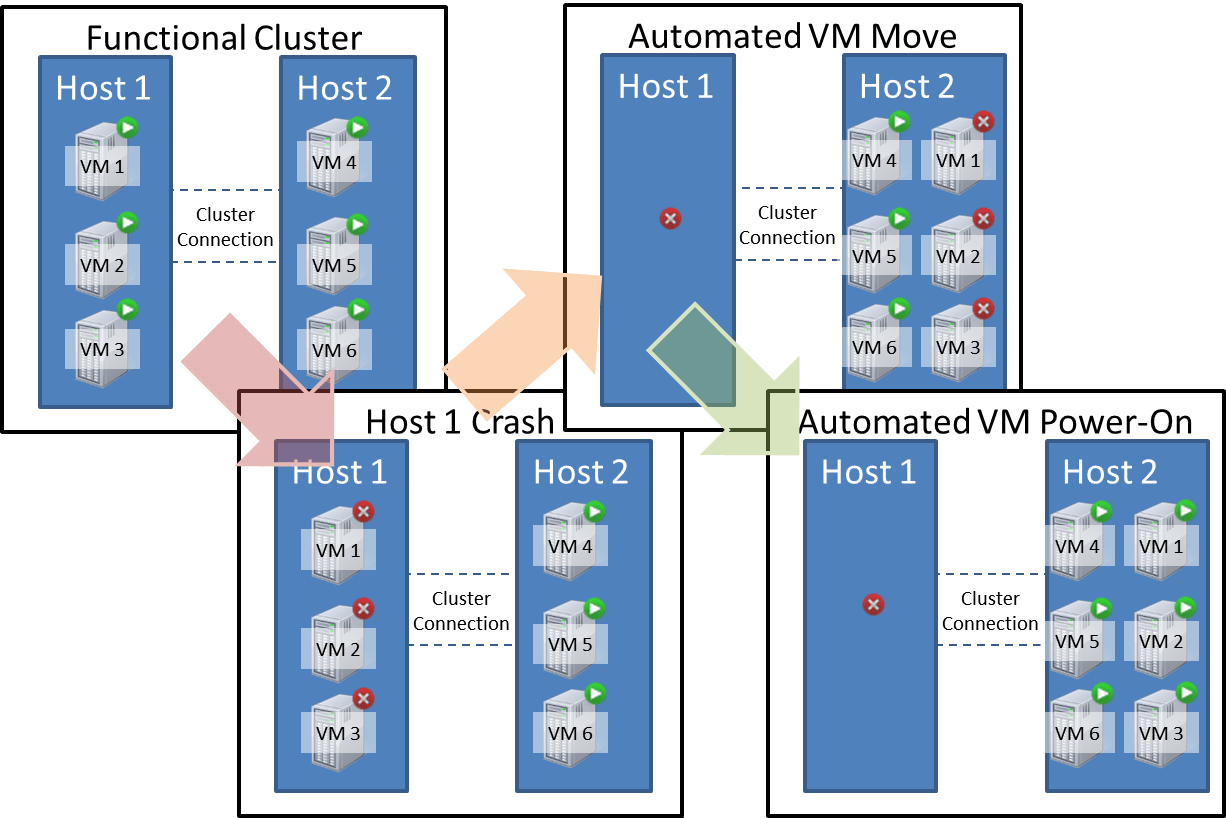
Although the VMs will be powered back on automatically, there may still be some recovery work necessary. Note that machines that were off when a host crashed will remain off, but will still be automatically migrated by the cluster service.
Salvaging a Crashed Virtual Machine
If you don’t have a cluster, you obviously won’t have the automated failover. However, if the storage device that your virtual machines were running from is still accessible, then the VHDs themselves can be quickly copied to another Hyper-V host and brought online in new virtual machines. Although it is technically possible to retrieve the entire virtual machine, its configuration files were set for a particular host or cluster and they’ll need some manual manipulation to be usable. If you documented the configuration of the virtual machines, you can build those configurations from scratch and just attach the copied VHDs. If you used a product such as Altaro Backup for Hyper-V, you could use its “Import Backup from Another Host” feature to restore the configuration files to the new location and then, if the VHD files from the crash are viable and of greater use than the ones from the backup, use them to overwrite the restored VHDs.
Crash Recovery Benefits in Hyper-V
Most of the benefits for crash recovery are found with a cluster configuration. The cluster service detects the loss of a node within seconds and automatically moves and restarts its VMs. Since virtual machines don’t have to go through the ponderous process of hardware initialization, they boot far faster than they would if they were not virtualized. No matter how many virtual machines were on a crashed host, they should all be booted again within a few minutes.
Even if you don’t have a cluster, there are benefits to operating within a virtualized environment that help to offset the risks of “putting all your eggs in one basket”. First, virtualization represents the ultimate in hardware abstraction. If you have a backup of the virtual machine or can salvage the VHDs, you can get those virtual machines running on any physical system that can run Hyper-V. You could run your online order entry system off a spare desktop computer, in a pinch. There’s no need to wait for replacement matching hardware before bringing the failed system(s) back online.
How Clustering Affects Deployment Planning
Because of the rapid recovery afforded by a cluster, it generally only takes a few critical virtual machines to justify the deployment of a cluster. Two (or more) physical hosts are obviously more expensive than one, but they are often much cheaper than if all contained virtual machines were running on dedicated hardware. The most expensive portion of a cluster is generally the shared storage aspect; each cluster node needs to have access to the same hard drive system to run the virtual machines from. However, prices for virtualization-ready NAS and SAN devices are constantly declining and software-based solutions that convert regular server hardware into NAS devices have improved significantly. Because they have the potential to reduce downtime from hours of involved work to minutes of automated recovery, these systems are generally well worth the investment – if your systems need that level of protection.
Looking Ahead to Hyper-V R3
The next version of Hyper-V will include a built-in replication mechanism that will address several concerns. One of them is for those shops that need better protection than a single host can provide but struggle with the overhead cost and maintenance of even the most basic shared storage setup. Replication will allow you to have Hyper-V periodically update an offline copy of a virtual machine with changes from the live copy. This replication doesn’t have the heartbeat mechanism of a cluster so it won’t allow for automated failover, but it can have a ready-to-go virtual machine on standby. Please remember that replication cannot ever replace backup; it does not provide any versioning or retention settings so it has almost no protection against malicious or accidental corruption, among other things.
Although the VMs will be powered back on automatically, there may still be some recovery work necessary. Note that machines that were off when a host crashed will remain off, but will still be automatically migrated by the cluster service.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


2 thoughts on "Hyper-V Host Failure: How to Prepare"
We were told that copying our vhd files from our hyper-v vm’s and then copying them over in a restore would be a good solution. However, in testing, copying the vhd’s back is giving us vm’s that won’t start. When we start them from the Server manager it says we don’t have permission to do that. From the cluster manager it just fails. Any ideas? We asked for an automated backup solution but didn’t get the go-ahead. Maybe this is related to AD? This is our first sever that uses AD (and also cluster/vm).