Save to My DOJO
In Part 1 of this article series, we saw how to check replication health status of virtual machines using Hyper-V Manager and the different health status a virtual machine can enter into. In Part 2, we’re going to explain in detail the different replication health status (Warning and Critical) a virtual machine can enter into and also point out the differences between “Critical” and “Warning” replication health status.
I have written this part of the article series after thoroughly understanding the impact of a “Warning” and “Critical” replication health status on Hyper-V Replica and why you should just not just call Microsoft Support professionals to troubleshoot the issues for you!
Replication Health Status shows “Warning”
A virtual machine can enter into “Warning” health status if 20% of the replication cycles have been missed or replica copies (HRL files) have not been replicated to the Replica Server for more than 1 hour. You might also see the virtual machine into such status if the Primary virtual machine replication is paused or initial replication has not been completed yet after enabling the Hyper-V replication. A virtual machine into “Warning” state looks like below:
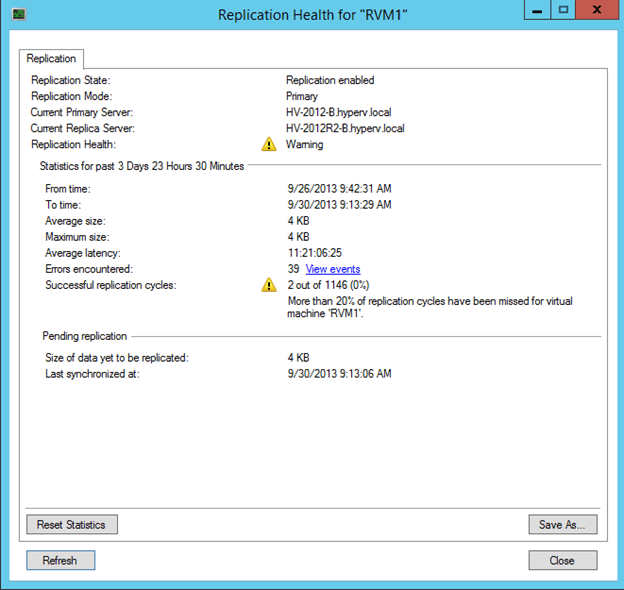
A replication cycle is considered missed if the Primary Server has not replicated HRL file (replica) within the default replication interval (5 minutes). As shown in the above screenshot, there were 2 successful replication cycles out of 1146 which indicates more than 20% of the total replication cycles were missed.
Hyper-V Primary Server will also generate an Event ID 32315 for virtual machines in “Warning” health status as shown in the below screenshot:
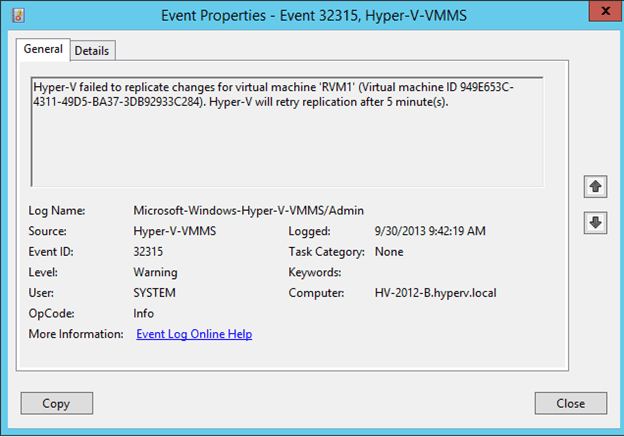
There will be multiple event entries logged with the same Event ID. Each entry provides the name of the virtual machine which is in “Warning” health status and the time it will take to retry the replication. The Event ID indicates failure with the replication but that does not mean that the replication is broken completely which is the case when a virtual machine shows “Critical” health status which is explained in the next section.
Replication Health Status shows “Critical”
In case a “Critical” health status is displayed for a virtual machine, it is necessary to understand why virtual machine enters into such replication health status.
A virtual machine can be in a “Critical” health status if Primary Server is not able to send the replication packets to the replica server due to network connectivity issues or issues with components of Primary or Replica Servers. Furthermore, a Primary virtual machine is considered “Critical” if Primary Server is not able to keep track of the changes. In most cases, such virtual machine requires resynchronization or you must fix the errors before Primary Server loses control over the tracked changes.
A Primary virtual machine can also be seen in “Critical” condition, if an administrator has paused the replication at the Replica Server. For example, you might have paused replication at Replica Virtual Machine due to some technical/business reasons. In that case, there is no need to fix the errors since this is done intentionally. In my opinion, Hyper-V replica should be smart enough to handle such situations. It makes no sense to put a virtual machine into “Critical” health status if an event is triggered administratively (e.g. Replica virtual machine is being paused by an administrator).
Opening the “Replication Health” page will show more information as to what is wrong with the virtual machine as shown in the below screenshot:
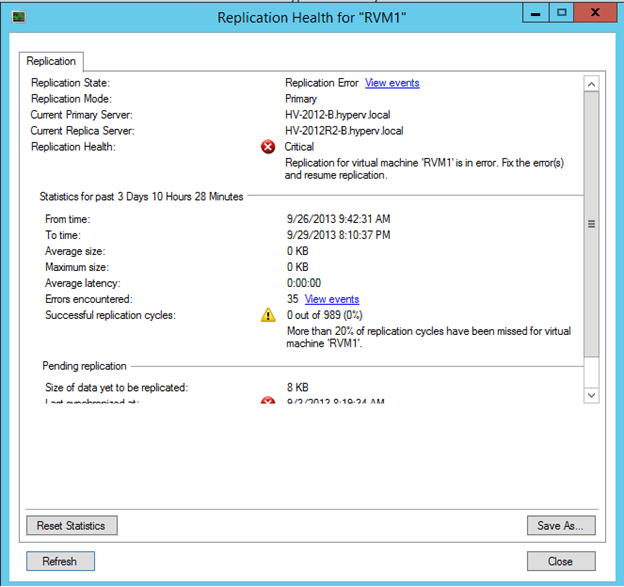
As you can see in the above screenshot, there are more than 20 percent of replication cycles have been missed for the virtual machine “RVM1” and the “Replication Health” indicates “Critical” for the virtual machine.
When a virtual machine is in “Critical” health status, Hyper-V Primary Server will generate Error messages in the event viewer (expand Application and Services Logs | Microsoft | Windows | Hyper-V-VMMS, and click on Admin). Different Event IDs will be generated for different reasons. Below shown are three types of error messages generated with three different Event IDs in the Event Viewer for the Primary Virtual Machine; Event ID 32088, 32022 and 29292.
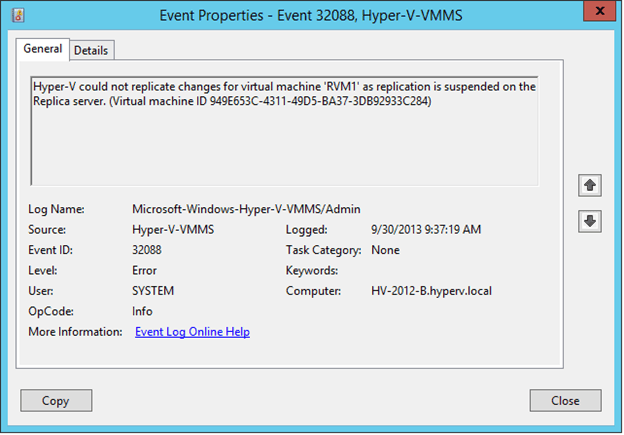
Event ID 32088 will be generated if the replication is suspended on the Replica Server as it is the case for virtual machine RVM1 which is shown in the above screenshot.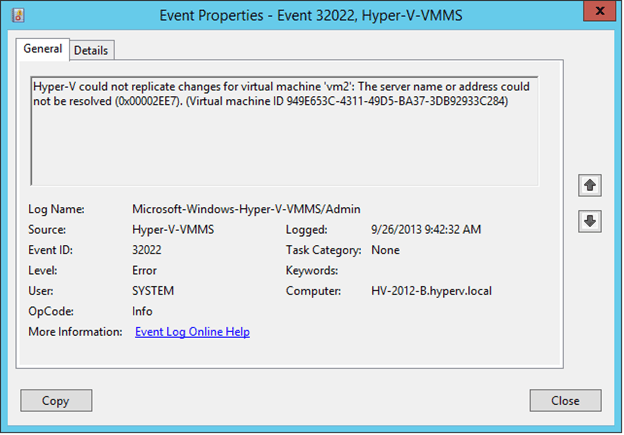
For Event ID 32022, it says that the Hyper-V Replica server name could not be resolved. The event does not mention the Replica Server name specifically but by looking at the event message it is understood that the Primary Server is trying to contact Replica Server before initiating the replication.
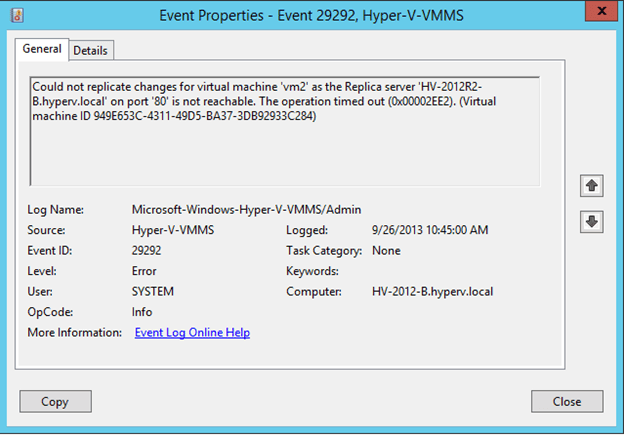
Event ID 29292 always indicates that there are some issues with the connectivity between the Hyper-V Primary Server and Replica Server as shown in the below screenshot:
On the “Replication Health” page, the “Replication Mode” indicates the type of replication (Incoming Replication (Replica Virtual Machine) or Outgoing Replication (Primary Virtual Machine)).
Remember that a Primary Server can also act as a Replica Server to accept incoming replication. So, you could have a mixture of virtual machines running on the same Hyper-V Server (e.g. Primary and Replica virtual machines). For a virtual machine, if the “Replication Mode” shows “Primary” that means the contents of this virtual machine are replicated to a Replica Server populated in the “Current Replica Server” column. On the other hand, if it shows “Replica” that means the replication is incoming and the replication packets are accepted from the Primary server name shown in the “Current Primary Server” column.
If “Replication Health” page shows “Critical” with a message; “Resynchronization is required for the virtual machine <VM Name>. Resume replication to start resynchronization”, then this virtual machine must be resynchronized with the Replica Virtual Machine. There are two ways to resynchronize the contents of the virtual machine; by resuming the replication on the Primary virtual machine or by using the PowerShell cmdlet.
Before you start resynchronization, you must address any connectivity issues between Primary and Replica Servers. In other words, you must make sure there is no any connection issue between Primary and Replica Servers before starting the resynchronization process. Explaining the resynchronization process is out of scope of this article but I will cover the resync process in detail in a separate post.
Differences between Warning and Critical Health Status
Now that you know the different replication replication health status a virtual machine can enter into, it is time to understand the difference between “Warning” and “Critical” health status.
“Warning” health status of a virtual machine does not mean that the replication is not at all working. Hyper-V Primary Server might have missed a few replication cycles but it still knows as to what to replicate in the next interval. In other words, Hyper-V Primary Server has not lost control over the tracked changes.
For virtual machines into “Critical” health status, consider into an actual “Critical” health status only if the following conditions are true:
– Primary Server is not able to reach Replica Server due to network connectivity for more than 1 hour and there are many changes occurring to the Primary virtual machine.
– Primary Server is not able to replicate HRL files due to low network bandwidth or storage related issues for more than 1 hour.
– Replica Virtual Machine is not paused administratively.
– You see one of the following messages on the replication health page:
- Replication for virtual machine <VM Name> is in error. Fix the error(s) and resume replication.
OR
- Resynchronization is required for the virtual machine <VM Name>. Resume replication to start resynchronization.
In other words, Primary Server has actually lost the control over the data it tracked and now it cannot determine as to what to replicate to the Replica Virtual Machine in the next interval. Thus, it requires administrators to fix the issue and in such situation a reysnnchronization of the complete contents of the Primary Virtual Machine would be necessary.
Conclusion
In this article we saw that a virtual machine can enter into different health status depending on the various conditions. We primarily focused on Warning and Critical health status of a virtual machine.
The article also highlights the actual differences between a virtual machine entering into “Warning” and “Critical” states. We learned that a virtual machine entering into “Warning” state does not indicate total replication failure but a “Critical” state of a virtual machine always indicates that replication is completely broken provided the conditions explained in the “Differences between Warning and Critical States“ section of this article are considered.


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!








7 thoughts on "How to Check Hyper-V Replica Health – Part 2"
Thank you for your great article!
What would be nice is for you to show a simple script to email if any warning or critical event happens. I would just like to check the server once a day. If the condition is not normal then send me an email so I can look into it. But having the script email as soon as there is a warning or a critical event would be nicer. I am not a programmer but I am trying to do this.
Thanks for this info. I have written up a guide on how to get email alerts on server 2012 when the Hyper V enters critical state. – http://www.phasercomputers.com.au/hyperv-replication-email-alerts-notification-failure/
Hi Nirmal. Great article, but, what we can do, powershell or anything, to fix warning or error in replication? When i got this erros i remove replication, delete old files and re-create replication.
Hi Bruno,
There are a few things to try when replication isn’t working, as outlined in this article and Part 1. First – check disk space and ensure that both source and destination Hyper-V hosts have plenty spare disk space. Next, I would check the error in Hyper-V Manager, which should tell you what the issue is, as above. Many times you don’t need to delete the replication and start from scratch (which can take some time if the VM disks are large or the link between the sites is slow), follow the steps in the article to run resynchronization, in my experience (I’ve been running Hyper-V Replica for several clients for many years now) that fixes most issues.
This page is a good resource, although slightly out of date, to look at.
Paul Schnackenburg, Altaro DOJO Technical Editor