Save to My DOJO

One of the many benefits of virtualization is the “abstraction” of hardware. This means that a virtualized operating system is never closely matched with the hardware that it lives on. This gives systems administrators access to a large number of previously unavailable capabilities. One of these is “high availability”. Freed from the constraints of the underlying hardware, virtual machines can be easily moved to other hardware. These moves can even be automated.
“High Availability” is not “Fault-Tolerance”
Newcomers to the world of virtualization often confuse high availability with fault tolerance. High availability allows virtual machines to be moved from one physical host to another without appreciable downtime for the virtual machine. This zero-downtime transition does require that all involved hardware be in working condition. In the event of hardware failure, most high availability technology (including Hyper-V’s) can automatically restart failed virtual machines on another host, but those virtual machines will experience downtime. This is still considered “high availability” because the virtual machines are only down for the amount of time it takes them to start back up in the new location. In order to achieve zero-downtime protection in the event of hardware failure, you will need a “fault-tolerant” solution. Hyper-V does not include a native fault-tolerance protection method for its virtual machines. If this is desired, there are third-party solutions for virtual machines. Some services and applications (like Microsoft Exchange) can be protected using multiple Hyper-V virtual machines and clustering schemes.
Shared Storage
In order to achieve high availability in Hyper-V, you’ll need a minimum of two physical hosts and some form of “shared storage”. Shared storage is a single device or device cluster than can be accessed by multiple servers simultaneously using a technology that emulates internal storage – usually iSCSI or fibrechannel. The hosts in your Hyper-V cluster are all connected to that shared storage and the VHD files for the virtual machines are run from it. Because the storage is shared, if one of the hosts crashes, the other host(s) can take over running those virtual machines automatically.
Shared Storage Affordability
Up until recently, shared storage was priced well out of the range of a great many smaller businesses, especially as budgets tightened under world-wide economic woes. However, the popularity of virtualization incentivized many companies to innovate reliable solutions at lower costs. It is now possible to purchase specialized hardware that has been certified to work with Hyper-V at a dramatically lower price point than was available even two years ago. If specialized hardware is still out of your budget range or if you’re just uncomfortable bringing in unfamiliar technology, software solutions are available that can be installed on general-purpose server class hardware to allow using its internal and connected storage as shared storage. A notable entry in this market is Microsoft’s iSCSI Software Target, which is the same technology that powers Windows Storage Server. With this software (or third-party alternatives) an existing Windows Server computer can be utilized as a SAN.
Traditionally, protecting the shared storage against being a single point of failure is where major costs have been introduced. SANs often contain multiple controllers, power supplies and network connections and implement RAID technologies to ensure that all components are redundant. Lower-cost entries have begun putting pricing pressure on the larger manufacturers and it is becoming increasingly possible to find affordable solutions that also provide redundancy. The aforementioned iSCSI software targets can also address this concern using multiple lower-cost devices or general-purpose server hardware. Two devices with Windows Storage Server or servers with Windows Server Enterprise or Datacenter edition and the iSCSI target can be clustered to provide high availability for your storage environment.
High Availability Benefits
Even with shared storage becoming more cost-friendly, building a highly available Hyper-V system is going to cost more than just consolidating onto a single physical device. That can make it a tougher sell than the basic hypervisor deployment.
Virtual Cluster vs. Physical Deployment Hardware Savings
The first place to make the comparison is against the non-virtualized equivalent. If you can get all the cluster equipment for less than it would have cost to deploy all of your virtualized machines as physical units, then you’ve still saved money and you’ve gained high availability.

Figure 1: 6 single points of failure vs. none (assuming internally redundant shared storage)
Reduced Planned Downtime
Are your users and clients accustomed to e-mails and messages indicating that certain systems will be offline for hours during a scheduled downtime window? These windows can be reduced, and in some cases completely eliminated. An administrator can transition all of the virtual machines from one host in the cluster to the others. Once it’s empty, the host can have its firmware, drivers, and host operating system updated and patched without service interruption. Depending upon business needs and confidence in the remainder of the cluster, this can occur at any time – even during normal business hours when your entire IT team is available and well-rested. Your shared storage might be the only equipment you’ll need to update outside normal service hours, but it’s also the only device that can be completely locked down and secured since nothing other than the Hyper-V hosts and storage administrators need to have direct access. With that level of external security, it can be acceptable in some environments to update the shared storage units less frequently than other production units. For most organizations, fewer hours spent in after-hours servicing translates into cost savings.
Reduced Unplanned Downtime and Rapid Fault Recovery
Using a single Hyper-V host magnifies the problem that physical deployments have always faced: if the host hardware fails, all services fail with it. If that host has been used to consolidate several physical servers, then you are at greater risk than if all machines were left on separate physical hosts. All those machines will remain offline until the hardware can be repaired or replaced. By contrast, if a clustered Hyper-V host fails, Hyper-V will automatically boot all failed virtual machines on another host in the cluster. The effect on those virtual machines will be exactly as if they’d just lost power unexpectedly. All of this will happen with a few seconds, so you’ll be able to confidently set your recovery time objective (RTO) for hardware failure down to seconds or minutes instead of the hours (or even days) of a non-virtualized or single-host deployment.
Implementing Shared Storage
The precise method of deploying any given shared storage scheme will vary depending on the hardware and software you are using. The basic process is to implement the shared storage first, connect the Hyper-V hosts to it, and add the hosts into a Failover Cluster.
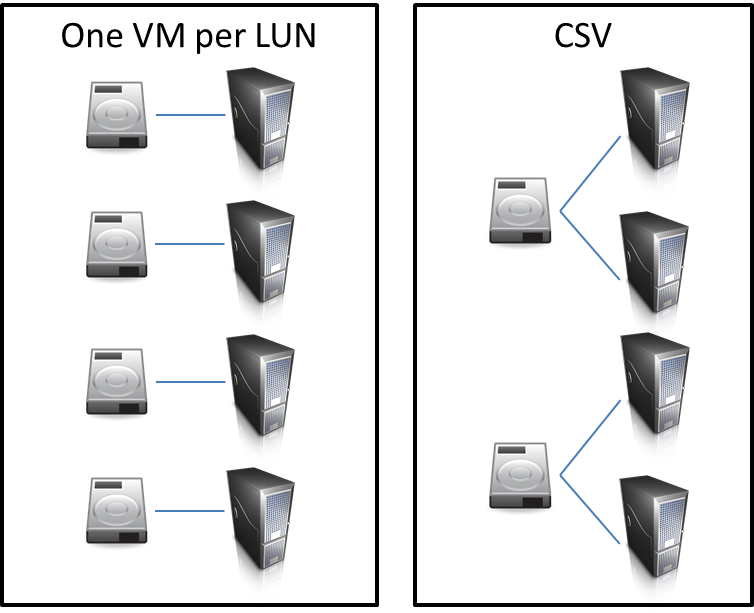
One VM per LUN or Cluster Shared Volumes?
The original method of shared storage from Hyper-V R1 was to place all the VHDs for a VM into a single LUN (Logical Unit Number: the acronym is a holdover from older SCSI terminology but in this usage it refers to a logical volume on a shared storage device) and not use that LUN for any other VM. The reason is that when a VM is transitioned from one host to another, ownership of the LUN must transfer with it. If any VHDs on that LUN belong to another VM, that VM will lose connectivity to its drives and blue screen. This is the most drastic restriction, but there are others. LUNs would have to be designed using calculations that allowed sufficient slack space for each VM’s storage needs separately. All devices have a limitation on LUN-count, although this is generally large enough that few installations will run into it. A more threatening restriction is connection count. Each Hyper-V host will need at least one connection per LUN that holds a virtual machine it can become owner of. Unlike LUN count limitations, connection count limitations can be relatively low.
To address the limitations of the one-VM-per-LUN model, Microsoft introduced Cluster Shared Volumes in Hyper-V R2. This technology allows multiple Hyper-V hosts to access separate virtual machines on the same volume at the same time. You can build one LUN that holds a large number of VHDs owned by separate VMs without fear of what will happen if a VM is transitioned from one host to another. This adds a little bit of a learning curve for anyone not familiar with this new technology, but the curve is fairly short and well worth the effort to learn.
Shared Storage Concerns
After cost and single-point-of-failure worries are addressed, there are only a few remaining issues, but they are important. The first is backup. Because a virtual machine could theoretically be on any host at any given time and could even transition during a backup operation, you must select backup software that is cluster aware if you intend to back up your virtual machines at the hypervisor level. If you will be using Cluster Shared Volumes, then you must be absolutely certain that your backup software is CSV-aware. Because CSVs present themselves to the hosts as a subdirectory of the C: drive and utilize the traditional NTFS file structure, it is tempting to treat them as any other directory tree. This is extremely dangerous behavior. Without triggering the proper Hyper-V mechanism (Redirected Access), it is entirely possible for activity on another host to corrupt the backup data and you will not be aware of the damage unless you attempt a restore. Double-check that any application you intend to deploy for backup specifically indicates that it can handle CSVs, as not many can. One that can is Altaro Backup for Hyper-V.
The second consideration is the physical network. In this setup, your virtual machines are actively running on one server but they are connected to their “local” drives over a network connection that they are sharing with other virtual machines. That network needs to be fast and it needs to not be contending with other network devices for bandwidth. The easiest way to ensure this is to use dedicated switching hardware for all iSCSI traffic. If you have the proper equipment and networking savvy, this can also be accomplishing by use of VLANs. A side benefit of this type of build is that the iSCSI device and its traffic is not reachable by anything other than your Hyper-V hosts, which adds a relatively high layer of security at relatively low cost.
The Future: Hyper-V R3
The next iteration of Hyper-V will include several improvements and new features related to this discussion, such as replication. Keep an eye out for future discussions!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


7 thoughts on "High Availability: Shared Storage in Hyper-V"
I’m in the process of setting up a new 2016 Hyper-V Failover cluster with 2 nodes and shard storage. This article suggests that with Hyper-V and Cluster Shared Volumes I can present one or two large LUNs and save all of the VMs and VHDs there. However, I also read https://www.altaro.com/hyper-v/storage-and-hyper-v-part-4-file-systems/ which leads me to believe this is not recommended and I would be best still having separate smaller LUNS for each VM. Can you expand on which is recommended and the pros and cons of each method?
This particular article just gives an overview comparison between cluster disks and Cluster Shared Volumes. It is not a design guide. The article that you linked is a little bit more of a design guide, although that’s not what it was written to be either. One Big RAID gives better performance because the work is spread across multiple platters. It also gives the best space per dollar ratio because you’ll use less overall space for redundancy. The downside to One Big RAID is that a redundancy failure scraps all of your data instead of only some of it. The antidote to that is using sufficient redundancy and monitoring.
After that, you decide LUN count. I don’t ever tell anyone what to do because that is a situational decision that requires intimate knowledge of the environment. I don’t like using a single big LUN because that would restrict portability possibilities and troubleshooting techniques. I would personally always use at least two. I would probably never place each VM on its own LUN because that’s just difficult to architect and wasteful of space and requires a great deal of micromanagement.
It’s great that VMs can fail to another node without too much impact. But what happens if the underlying LUN fails in the CSV?
For example, let’s say I have 2 nodes, each with 1TB HDD. I add both HDDs to the CSV and any VMs can access them. If node1 dies, VMs will failover to node2, but the storage on node1 will be dead.
In that case, would I need a replica of some sort setup for the storage? Or would I need some sort of backup solution? What would be the best practice or recommendation for this scenario?
If the LUN is lost, everything in it is lost.
If you must choose, backup is your first choice. If you have a solid backup system and budget left over, look into replica. They are different technologies with different purposes.