Save to My DOJO
Table of contents
- Why Did We Abandon Practices from 2008 R2?
- What Do Cluster Networks Need to Accomplish for Hyper-V?
- Fundamental Terminology and Concepts
- How Does Microsoft Failover Clustering Identify a Network?
- Architectural Goals
- Architecting IP Addresses
- Implementing Hyper-V Cluster Networks
- What About Traffic Prioritization?
- What About Hyper-V QoS?
We recently published a quick tip article recommending the number of networks you should use in a cluster of Hyper-V hosts. I want to expand on that content to make it clear why we’ve changed practice from pre-2012 versions and how we arrive at this guidance. Use the previous post for quick guidance; read this one to learn the supporting concepts. These ideas apply to all versions from 2012 onward.
Why Did We Abandon Practices from 2008 R2?
If you dig on TechNet a bit, you can find an article outlining how to architect networks for a 2008 R2 Hyper-V cluster. While it was perfect for its time, we have new technologies that make its advice obsolete. I have two reasons for bringing it up:
- Some people still follow those guidelines on new builds — worse, they recommend it to others
- Even though we no longer follow that implementation practice, we still need to solve the same fundamental problems
We changed practices because we gained new tools to address our cluster networking problems.
What Do Cluster Networks Need to Accomplish for Hyper-V?
Our root problem has never changed: we need to ensure that we always have enough available bandwidth to prevent choking out any of our services or inter-node traffic. In 2008 R2, we could only do that by using multiple physical network adapters and designating traffic types to individual pathways. Note: It was possible to use third-party teaming software to overcome some of that challenge, but that was never supported and introduced other problems.
Starting from our basic problem, we next need to determine how to delineate those various traffic types. That original article did some of that work. We can immediately identify what appears to be four types of traffic:
- Management (communications with hosts outside the cluster, ex: inbound RDP connections)
- Standard inter-node cluster communications (ex: heartbeat, cluster resource status updates)
- Cluster Shared Volume traffic
- Live Migration
However, it turns out that some clumsy wording caused confusion. Cluster communication traffic and Cluster Shared Volume traffic are exactly the same thing. That reduces our needs to three types of cluster traffic.
What About Virtual Machine Traffic?
You might have noticed that I didn’t say anything about virtual machine traffic above. Same would be true if you were working up a different kind of cluster, such as SQL. I certainly understand the importance of that traffic; in my mind, service traffic prioritizes above all cluster traffic. Understand one thing: service traffic for external clients is not clustered. So, your cluster of Hyper-V nodes might provide high availability services for virtual machine vmabc, but all of vmabc‘s network traffic will only use its owning node’s physical network resources. So, you will not architect any cluster networks to process virtual machine traffic.
As for preventing cluster traffic from squelching virtual machine traffic, we’ll revisit that in an upcoming section.
Fundamental Terminology and Concepts
These discussions often go awry over a misunderstanding of basic concepts.
- Cluster Name Object: A Microsoft Failover Cluster has its own identity separate from its member nodes known as a Cluster Name Object (CNO). The CNO uses a computer name, appears in Active Directory, has an IP, and registers in DNS. Some clusters, such as SQL, may use multiple CNOs. A CNO must have an IP address on a cluster network.
- Cluster Network: A Microsoft Failover Cluster scans its nodes and automatically creates “cluster networks” based on the discovered physical and IP topology. Each cluster network constitutes a discrete communications pathway between cluster nodes.
- Management network: A cluster network that allows inbound traffic meant for the member host nodes and typically used as their default outbound network to communicate with any system outside the cluster (e.g. RDP connections, backup, Windows Update). The management network hosts the cluster’s primary cluster name object. Typically, you would not expose any externally-accessible services via the management network.
- Access Point (or Cluster Access Point): The IP address that belongs to a CNO.
- Roles: The name used by Failover Cluster Management for the entities it protects (e.g. a virtual machine, a SQL instance). I generally refer to them as services.
- Partitioned: A status that the cluster will give to any network on which one or more nodes does not have a presence or cannot be reached.
- SMB: ALL communications native to failover clustering use Microsoft’s Server Message Block (SMB) protocol. With the introduction of version 3 in Windows Server 2012, that now includes innate multi-channel capabilities (and more!)
Are Microsoft Failover Clusters Active/Active or Active/Passive?
Microsoft Failover Clusters are active/passive. Every node can run services at the same time as the other nodes, but no single service can be hosted by multiple nodes. In this usage, “service” does not mean those items that you see in the Services Control Panel applet. It refers to what the cluster calls “roles” (see above). Only one node will ever host any given role or CNO at any given time.
How Does Microsoft Failover Clustering Identify a Network?
The cluster decides what constitutes a network; your build guides it, but you do not have any direct input. Any time the cluster’s network topology changes, the cluster service re-evaluates.
First, the cluster scans a node for logical network adapters that have IP addresses. That might be a physical network adapter, a team’s logical adapter, or a Hyper-V virtual network adapter assigned to the management operating system. It does not see any virtual NICs assigned to virtual machines.
For each discovered adapter and IP combination on that node, it builds a list of networks from the subnet masks. For instance, if it finds an adapter with an IP of 192.168.10.20 and a subnet mask of 255.255.255.0, then it creates a 192.168.10.0/24 network.
The cluster then continues through all of the other nodes, following the same process.
Be aware that every node does not need to have a presence in a given network in order for failover clustering to identify it; however, the cluster will mark such networks as partitioned.
What Happens if a Single Adapter has Multiple IPs?
If you assign multiple IPs to the same adapter, one of two things will happen. Which of the two depends on whether or not the secondary IP shares a subnet with the primary.
When an Adapter Hosts Multiple IPs in Different Networks
The cluster identifies networks by adapter first. Therefore, if an adapter has multiple IPs, the cluster will lump them all into the same network. If another adapter on a different host has an IP in one of the networks but not all of the networks, then the cluster will simply use whichever IPs can communicate.
As an example, see the following network:
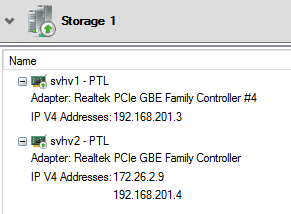
The second node has two IPs on the same adapter and the cluster has added it to the existing network. You can use this to re-IP a network with minimal disruption.
A natural question: what happens if you spread IPs for the same subnet across different existing networks? I tested it a bit and the cluster allowed it and did not bring the networks down. However, it always had the functional IP pathway to use, so that doesn’t tell us much. Had I removed the functional pathways, then it would have collapsed the remaining IPs into an all-new network and it would have worked just fine. I recommend keeping an eye on your IP scheme and not allowing things like that in the first place.
When an Adapter Hosts Multiple IPs in the Same Network
The cluster will pick a single IP in the same subnet to represent the host in that network.
What if Different Adapters on the Same Host have an IP in the Same Subnet?
The same outcome occurs as if the IPs were on the same adapter: the cluster picks one to represent the cluster and ignores the rest.
The Management Network
All clusters (Hyper-V, SQL, SOFS, etc.) require a network that we commonly dub Management. That network contains the CNO that represents the cluster as a singular system. The management network has little importance for Hyper-V, but external tools connect to the cluster using that network. By necessity, the cluster nodes use IPs on that network for their own communications.
The management network will also carry cluster-specific traffic. More on that later.
Note: Replica uses a management network.
Cluster Communications Networks (Including Cluster Shared Volume Traffic)
A cluster communications network will carry:
- Cluster heartbeat information. Each node must hear from every other node within a specific amount of time (1 second by default). If it does not hear from a minimum of nodes to maintain quorum, then it will begin failover procedures. Failover is more complicated than that, but beyond the scope of this article.
- Cluster configuration changes. If any configuration item changes, whether to the cluster’s own configuration or the configuration or status of a protected service, the node that processes the change will immediately transmit to all of the other nodes so that they can update their own local information store.
- Cluster Shared Volume traffic. When all is well, this network will only carry metadata information. Basically, when anything changes on a CSV that updates its volume information table, that update needs to be duplicated to all of the other nodes. If the change occurs on the owning node, less data needs to be transmitted, but it will never be perfectly quiet. So, this network can be quite chatty, but will typically use very little bandwidth. However, if one or more nodes lose direct connectivity to the storage that hosts a CSV, all of its I/O will route across a cluster network. Network saturation will then depend on the amount of I/O the disconnected node(s) need(s).
Live Migration Networks
That heading is a bit of misnomer. The cluster does not have its own concept of a Live Migration network per se. Instead, you let the cluster know which networks you will permit to carry Live Migration traffic. You can independently choose whether or not those networks can carry other traffic.
Other Identified Networks
The cluster may identify networks that we don’t want to participate in any kind of cluster communications at all. iSCSI serves as the most common example. We’ll learn how to deal with those.
Architectural Goals
Now we know our traffic types. Next, we need to architect our cluster networks to handle them appropriately. Let’s begin by understanding why you shouldn’t take the easy route of using a singular network. A minimally functional Hyper-V cluster only requires that “management” network. Stopping there leaves you vulnerable to three problems:
- The cluster will be unable to select another IP network for different communication types. As an example, Live Migration could choke out the normal cluster hearbeat, causing nodes to consider themselves isolated and shut down
- The cluster and its hosts will be unable to perform efficient traffic balancing, even when you utilize teams
- IP-based problems in that network (even external to the cluster) could cause a complete cluster failure
Therefore, you want to create at least one other network. In the pre-2012 model we could designate specific adapters to carry specific traffic types. In the 2012 and later model, we simply create at least one more additional network to allow cluster communications but not client access. Some benefits:
- Clusters of version 2012 or new will automatically employ SMB multichannel. Inter-node traffic (including Cluster Shared Volume data) will balance itself without further configuration work.
- The cluster can bypass trouble on one IP network by choosing another; you can help by disabling a network in Failover Cluster Manager
- Better load balancing across alternative physical pathways
The Second Supporting Network… and Beyond
Creating networks beyond the initial two can add further value:
- If desired, you can specify networks for Live Migration traffic, and even exclude those from normal cluster communications. Note: For modern deployments, doing so typically yields little value
- If you host your cluster networks on a team, matching the number of cluster networks to physical adapters allows the teaming and multichannel mechanisms the greatest opportunity to fully balance transmissions. Note: You cannot guarantee a perfectly smooth balance
Architecting Hyper-V Cluster Networks
Now we know what we need and have a nebulous idea of how that might be accomplished. Let’s get into some real implementation. Start off by reviewing your implementation choices. You have three options for hosting a cluster network:
- One physical adapter or team of adapters per cluster network
- Convergence of one or more cluster networks onto one or more physical teams or adapters
- Convergence of one or more cluster networks onto one or more physical teams claimed by a Hyper-V virtual switch
A few pointers to help you decide:
- For modern deployments, avoid using one adapter or team for a cluster network. It makes poor use of available network resources by forcing an unnecessary segregation of traffic.
- I personally do not recommend bare teams for Hyper-V cluster communications. You would need to exclude such networks from participating in a Hyper-V switch, which would also force an unnecessary segregation of traffic.
- The most even and simple distribution involves a singular team with a Hyper-V switch that hosts all cluster network adapters and virtual machine adapters. Start there and break away only as necessary.
- A single 10 gigabit adapter swamps multiple gigabit adapters. If your hosts have both, don’t even bother with the gigabit.
To simplify your architecture, decide early:
- How many networks you will use. They do not need to have different functions. For example, the old management/cluster/Live Migration/storage breakdown no longer makes sense. One management and three cluster networks for a four-member team does make sense.
- The IP structure for each network. For networks that will only carry cluster (including intra-cluster Live Migration) communication, the chosen subnet(s) do not need to exist in your current infrastructure. As long as each adapter in a cluster network can reach all of the others at layer 2 (Ethernet), then you can invent any IP network that you want.
I recommend that you start off expecting to use a completely converged design that uses all physical network adapters in a single team. Create Hyper-V network adapters for each unique cluster network. Stop there, and make no changes unless you detect a problem.
Comparing the Old Way to the New Way (Gigabit)
Let’s start with a build that would have been common in 2010 and walk through our options up to something more modern. I will only use gigabit designs in this section; skip ahead for 10 gigabit.
In the beginning, we couldn’t use teaming. So, we used a lot of gigabit adapters:

There would be some variations of this. For instance, I would have added another adapter so that I could use MPIO with two iSCSI networks. Some people used Fiber Channel and would not have iSCSI at all.
Important Note: The “VMs” that you see there means that I have a virtual switch on that adapter and the virtual machines use it. It does not mean that I have created a VM cluster network. There is no such thing as a VM cluster network. The virtual machines are unaware of the cluster and they will not talk to it (if they do, they’ll use the Management access point like every other non-cluster system).
Then, 2012 introduced teaming. We could then do all sorts of fun things with convergence. My very least favorite:
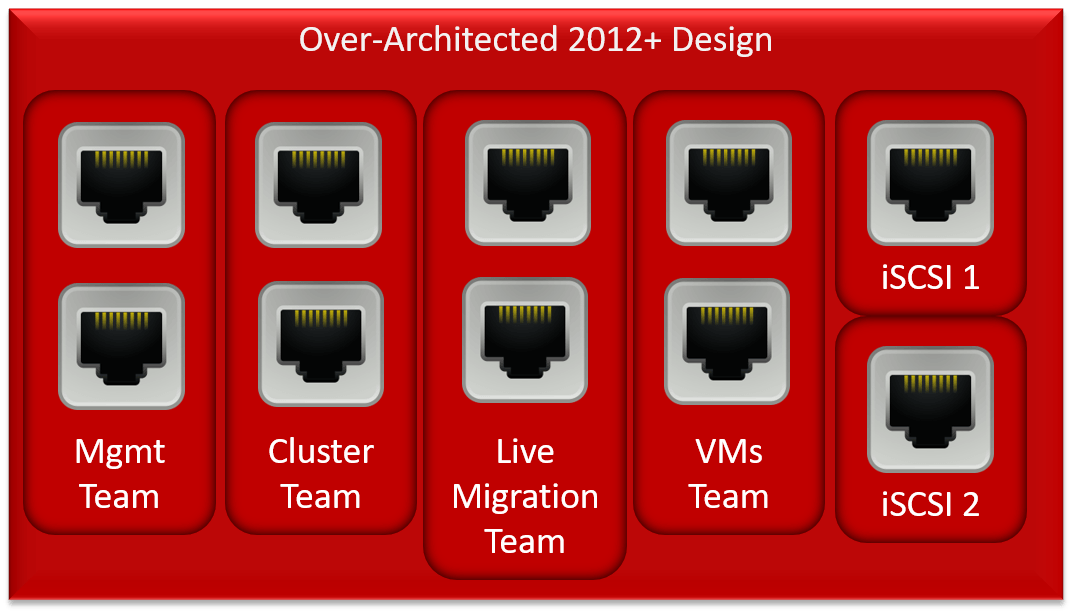
This build takes teams to an excess. Worse, the management, cluster, and Live Migration teams will be idle almost all the time, meaning that this 60% of this host’s networking capacity will be generally unavailable.
Let’s look at something a bit more common. I don’t like this one either, but I’m not revolted by it either:
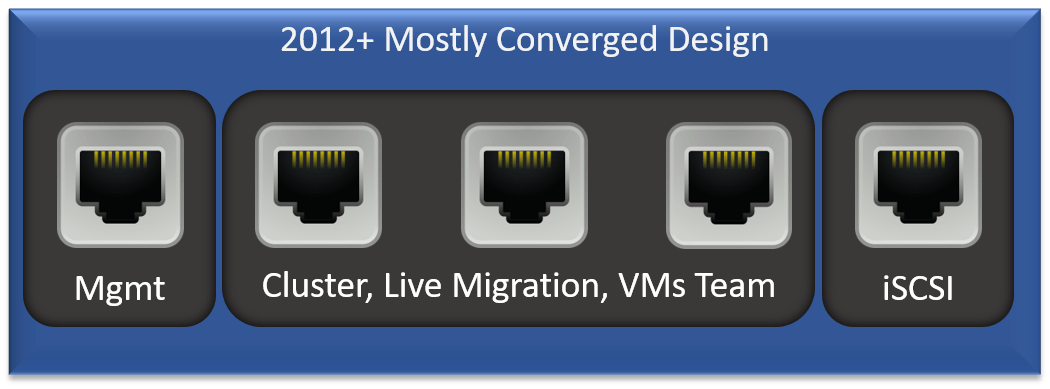
A lot of people like that design because, so they say, it protects the management adapter from problems that affect the other roles. I cannot figure out how they perform that calculus. Teaming addresses any probable failure scenarios. For anything else, I would want the entire host to fail out of the cluster. In this build, a failure that brought the team down but not the management adapter would cause its hosted VMs to become inaccessible because the node would remain in the cluster. That’s because the management adapter would still carry cluster heartbeat information.
My preferred design follows:

Now we are architected against almost all types of failure. In a “real-world” build, I would still have at least two iSCSI NICs using MPIO.
What is the Optimal Gigabit Adapter Count?
Because we had one adapter per role in 2008 R2, we often continue using the same adapter count in our 2012+ builds. I don’t feel that’s necessary for most builds. I am inclined to use two or three adapters in data teams and two adapters for iSCSI. For anything past that, you’ll need to have collected some metrics to justify the additional bandwidth needs.
10 Gigabit Cluster Network Design
10 gigabit changes all of the equations. In reasonable load conditions, a single 10 gigabit adapter moves data more than 10 times faster than a single gigabit adapter. When using 10 GbE, you need to change your approaches accordingly. First, if you have both 10GbE and gigabit, just ignore the gigabit. It is not worth your time. If you really want to use it, then I would consider using it for iSCSI connections to non-SSD systems. Most installations relying on iSCSI-connected spinning disks cannot sustain even 2 Gbps, so gigabit adapters would suffice.

Logical Adapter Counts for Converged Cluster Networking
I didn’t include the Hyper-V virtual switch in any of the above diagrams, mostly because it would have made the diagrams more confusing. However, I would use a Hyper-V team to host all of the logical adapters necessary. For a non-Hyper-V cluster, I would create a logical team adapter for each role. Remember that on a logical team, you can only have a single logical adapter per VLAN. The Hyper-V virtual switch has no such restrictions. Also remember that you should not use multiple logical team adapters on any team that hosts a Hyper-V virtual switch. Some of the behavior is undefined and your build might not be supported.
I would always use these logical/virtual adapter counts:
- One management adapter
- A minimum of one cluster communications adapter up to n-1, where n is the number of physical adapters in the team. You can subtract one because the management adapter acts as a cluster adapter as well
In a gigabit environment, I would add at least one logical adapter for Live Migration. That’s optional because, by default, all cluster-enabled networks will also carry Live Migration traffic.
In a 10 GbE environment, I would not add designated Live Migration networks. It’s just logical overhead at that point.
In a 10 GbE environment, I would probably not set aside physical adapters for storage traffic. At those speeds, the differences in offloading technologies don’t mean that much.
Architecting IP Addresses
Congratulations! You’ve done the hard work! Now you just need to come up with an IP scheme. Remember that the cluster builds networks based on the IPs that it discovers.
Every network needs one IP address for each node. Any network that contains an access point will need an additional IP for the CNO. For Hyper-V clusters, you only need a management access point. The other networks don’t need a CNO.
Only one network really matters: management. Your physical nodes must use that to communicate with the “real” network beyond. Choose a set of IPs available on your “real” network.
For all the rest, the member IPs only need to be able to reach each other over layer 2 connections. If you have an environment with no VLANs, then just make sure that you pick IPs in networks that don’t otherwise exist. For instance, you could use 192.168.77.0/24 for something, as long as that’s not a “real” range on your network. Any cluster network without a CNO does not need to have a gateway address, so it doesn’t matter that those networks won’t be routable. It’s preferred, in fact.
Implementing Hyper-V Cluster Networks
Once you have your architecture in place, you only have a little work to do. Remember that the cluster will automatically build networks based on the subnets that it discovers. You only need to assign names and set them according to the type of traffic that you want them to carry. You can choose:
- Allow cluster communication (intra-node heartbeat, configuration updates, and Cluster Shared Volume traffic)
- Allow client connectivity to cluster resources (includes cluster communication) and cluster communications (you cannot choose client connectivity without cluster connectivity)
- Prevent participation in cluster communications (often used for iSCSI and sometimes connections to external SMB storage)
As much as I like PowerShell for most things, Failover Cluster Manager makes this all very easy. Access the Networks tree of your cluster:
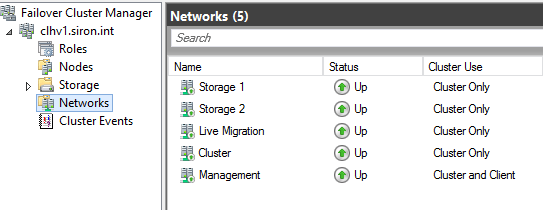
I’ve already renamed mine in accordance with their intended roles. A new build will have “Cluster Network”, “Cluster Network 1”, etc. Double-click on one to see which IP range(s) it assigned to that network:
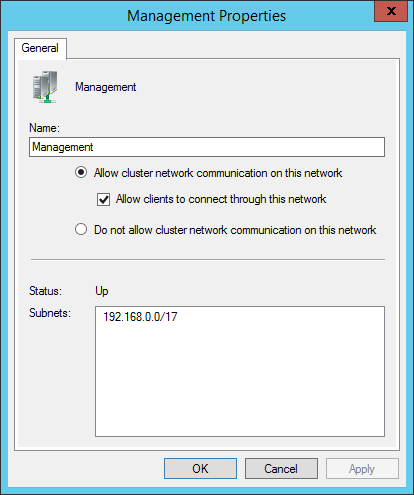
Work your way through each network, setting its name and what traffic type you will allow. Your choices:
- Allow cluster network communication on this network AND Allow clients to connect through this network: use these two options together for the management network. If you’re building a non-Hyper-V cluster that needs access points on non-management networks, use these options for those as well. Important: The adapters in these networks SHOULD register in DNS.
- Allow cluster network communication on this network ONLY (do not check Allow clients to connect through this network): use for any network that you wish to carry cluster communications (remember that includes CSV traffic). Optionally use for networks that will carry Live Migration traffic (I recommend that). Do not use for iSCSI networks. Important: The adapters in these networks SHOULD NOT register in DNS.
- Do not allow cluster network communication on this network: Use for storage networks, especially iSCSI. I also use this setting for adapters that will use SMB to connect to a storage server running SMB version 3.02 in order to run my virtual machines. You might want to use it for Live Migration networks if you wish to segregate Live Migration from cluster traffic (I do not do or recommend that).
Once done, you can configure Live Migration traffic. Right-click on the Networks node and click Live Migration Settings:
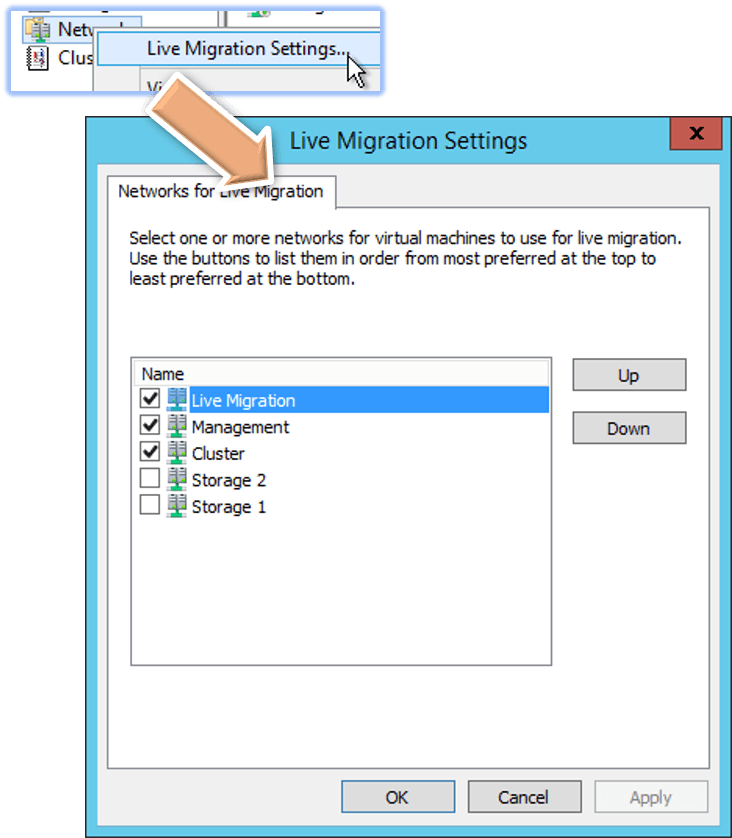
Check a network’s box to enable it to carry Live Migration traffic. Use the Up and Down buttons to prioritize.
What About Traffic Prioritization?
In 2008 R2, we had some fairly arcane settings for cluster network metrics. You could use those to adjust which networks the cluster would choose as alternatives when a primary network was inaccessible. We don’t use those anymore because SMB multichannel just figures things out. However, be aware that the cluster will deliberately choose Cluster Only networks over Cluster and Client networks for inter-node communications.
What About Hyper-V QoS?
When 2012 first debuted, it brought Hyper-V networking QoS along with it. That was some really hot new tech, and lots of us dove right in and lost a lot of sleep over finding the “best” configuration. And then, most of us realized that our clusters were doing a fantastic job balancing things out all on their own. So, I would recommend that you avoid tinkering with Hyper-V QoS unless you have tried going without and had problems. Before you change QoS, determine what traffic needs to be attuned or boosted before you change anything. Do not simply start flipping switches, because the rest of us already tried that and didn’t get results. If you need to change QoS, start with this TechNet article.
Your thoughts?
Does your preferred network management system differ from mine? Have you decided to give my arrangement a try? How id you get on? Let me know in the comments below, I really enjoy hearing from you guys!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author

Eric Siron


62 thoughts on "How to Architect and Implement Networks for a Hyper-V Cluster"
Thanks Eric, just what I needed to know 😉
Cheers
Juri
We have windows teaming in our Hyper-V host(Windows 2012 R2) with Dynamic load balancing. We are facing strange issue as one of the team adapter randomly stopping working . This issue come up sometimes more than a month. For time being , we have only solution to enabled/disabled the adapter and it works. Please suggest, if anyone had similar issue or any solution.
Very good. Since w2012 I have been confused trying to sort these details.
Question, I have a gigabit network infrastructure and use teams for my cluster client network, but for the cluster only network I have directly connected LAN cables (no switch) between my two hosts. I am thinking of replacing the directly connected network cards with a 10 gigabit card. I am thinking that will economically reduce live migration time and reduce network congestion on the main network at a critical point? What do you think?
“Economically” is in the eye of the beholder. If that’s a problem that you encounter often enough to want to solve, then your solution will work. Forgoing a switch with a crossover cable should keep the price tolerable.
Thank you Eric
Hi Ken, Are you using Team for directly connected LAN cable between two host? Actually, we are facing issue with directly connected cable when they are in Teams other wise single cable it works fine. Could you please suggest.
Hi Eric,
I just went through this entire tutorial (Which is Excellent, BTW, Thanks) the point at which I had the most trouble was at “Create Hyper-V network adapters for each unique cluster network.”. That is not described or linked here that I could see. And that process requires adding Management OS NICs via PowerShell, through the commands:
Add-VMNetworkAdapter –ManagementOS –Name “Mgmt” –SwitchName “Switch1”
and
Set-VMNetworkAdapterVlan -ManagementOS -VMNetworkAdapterName “Mgmt” -Access -VlanId 10
Hinting at how to perform this process I think would be helpful for future readers. Great Article! Thanks Again.
Good point, we did more “architect” than “implement”. Thanks for the addition!
Hi we want to create a hyper-v cluster with two network adapter , how we can use i, i do some google search but i found all blogs talks about 4 networks for cluster (Management-Cluster-Live Migration-ISCSI) so can i use those network on two physical network adapter ?
Put a team on the physical adapters, a virtual switch on the team, and virtual adapters on the switch. https://www.altaro.com/hyper-v/complete-guide-hyper-v-networking/
Great articles, thank you. I have a question or two. I have a production 2012 R2 Hyper-V 4 node cluster that was configured in the old 2008 mindset with 4 logical switches using SCVMM (mgmt, VMs, cluster, and migration), all connected to a NetApp, which is connected via iSCSI using 2 additional 1 GB NICs (not configured through SCVMM). We are implementing a new Pure storage system that will connect the new storage to our Cisco switches via 10 GB SFP and each of our hosts will have 2 10 GB SFP ports added as well.
I’m hoping to run both storage systems simultaneously until I complete migrating all of the the VM storage to the new storage system. So would I actually create a VSwitch using both 10 GB NICs in a team and create a virtual network adapter for each network, including the iSCSI traffic to the new storage system? And if so, should that iSCSI network be set for cluster only in Failover Cluster Manager cluster use setting, or should it be set to None?
Great article, Eric – this stuff has come along way over the years.
Regarding your statement on the “mostly converged design”;
“In this build, a failure that brought the team down but not the management adapter would cause its hosted VMs to become inaccessible because the node would remain in the cluster.”
I thought the management network carried host-specific traffic (standard RDP, domain traffic, AV etc). Is it not the cluster network which carries the traffic that determines health? And if so, a failure in the cluster/vm/LM team would trigger a host to be removed from the host, even if the MGMT network remained up, or am I mistaken?
I’ve been lumped with a couple of new servers with 4 x intel 1Gbit NICS and 2 x onboard 1Gbit NIC’s, so I’m trying to look at make the most use of them as possible, and I don’t really want to create a team with different brands of hardware – Storage is direct via 25Gbit (Starwind Virtual SAN), so I just have a few outstanding decisions to make.
Thanks!
A cluster has three types of networks: management cluster, cluster-only, and none of the above. There isn’t any management-only network. The cluster will prefer the cluster-only network for inter-node communication, but it will use the management network. That said, each VM has an option to set its vNIC as “protected”, in which case it should failover if it can’t reach the network. I do not know the mechanism that it uses to determine if it has network connectivity, and I have seen reports that it doesn’t always work as expected. YMMV.
As for NIC usage… I’m on the fence. I really hate buying hardware and not using it. I have an almost visceral reaction to the idea. Buuuuuuuut… six gigabit NICs is just a mess even in the best cases. The “best” thing is to disable the onboards and use the other 4 in a converged team. If you use the 4 in a team for VMs and the 2 in a team for management, then you have to rely on the “protected network” setting working as desired. Or you can just play the odds that you’ll likely never lose the guest network entirely.
Good day, Eric.
Thank’s for your job. I have one Q.
In my instance (4 nodes, each has 2 physical 10 Gb NICs.) i want to use MPIO (not TEAM) for iSCSI communication with my storage (only SSD). So, what i,m going to do? Cannot clearly to understand.
I’m using two of my physical NIC’s for DATA traffic (using MPIO) for ex. 192.168.100.0/24 (which is my real net), and for my MGMT and LiveMigration traffic i created vEthernet (Hyper-V clustered role, forget to say) connection, for ex. 10.10.10.0/24 which is only cluster net. Is it correct?
Thank you for your answer;)
I’m not understanding how many actual physical NICs you have. It reads like the box only has two but you’re using two for data?
Yes, it has 2 physical NIC’s (it’s a HPE 536LOM ib blade server) but also each physical NIC has 4 flexNIC’s (little bit hard to understand if never use it). The main Q for me, how to use it correct. Each physical NIC (2) is 10 Gb NIC’s. And you can make 4 flex from 1 “real” and control the bandwidth. So, i suppose to make 1 10Gb – for data and one for MGMT (LM and Heartb.) is it enough in case of MPIO?
In that build, you really only have two “real” pathways for load-balancing. So, you want to give your system at least two opportunities to balance each traffic type. MPIO can’t directly access the pathways in this case, but you can give the lower-level load balancers a chance. So, create at least two distinct IP endpoints for MPIO. You can do that by creating a virtual switch on all flexNICs and creating at least two management operating system virtual NICs just for iSCSI. Your second option is to create a virtual switch on only two of the flexNICs and set aside the other two for iSCSI. I would probably choose the latter because it most closely mirrors what I would do on a system with four real physical NICs and it will probably give you the most granular control over your iSCSI bandwidth management.
Thank’s for the answer.
In my case i can create 8 flexNIC’s (4 on each real NIC). That’s why, i suppose to share 1 to MGMT, 2 for MPIO, and 1 for domain network. Cant’s axactly understand what do mean saing “creating at least two management operating system virtual NICs just for iSCSI”. I create 2 connections for MPIO which is for iSCSI connection, or i am wrong?
Thank’s again
You can use all of the FlexNICs in a virtual switch and create virtual adapters for all the things.
Or you can use some of the FlexNICs in a virtual switch and use the remaining FlexNICs for iSCSI. I would do this one.
Good day, Eric.
I want to clarify one thing.
Have an instance (4 nodes in cluster, each node has 2 NICs – 10Gb each)
So, i want to use MPIO instead of TEAMing. That is why i give to this NIC’s ip’s from my real network (for ex. 192.168.100.10, 192.168.100.11) for data and connection with storage (SSD only) and what about MGMT and LIVE MIG in this case? Cluster role is Hyper-V. I need to make a virt switch with ip 10.10.10.10 (for ex.) which is not in my network, correct?
Thank’s a lot!
Thanks Eric great article! I’m hoping you can clarify one item for me, here is my scenario, 2016 HV cluster, 6 x 10G NIC SET team with IOV. Based on your article I’m thinking of just going with 2 vNICs on the host, 1 management and 1 cluster only. Management vNIC would be on our live infrastructure and Cluster only vNIC would be layer 2 only, different subnet non-routable IPs on the same vlan. Also, I will be implementing iWARP RDMA to hopefully take advantage of both SMB direct and multichannel in live migration. Given that scenario and specifically with the goal for SMB multichannel I believe I must allow both networks for live migration is that correct or do you have any other thoughts/concerns?
Thanks! Sam
Yes, that looks like the configuration that I would use myself.
Hi Eric,
Great post. I just have one question. In almost every article I read it says to not run iSCSI traffic through a team. But in your article your recommended network architecture is doing just that using 10Gb NICs. I thought there are issues running iSCSI through a team of adapters and that MPIO should be used on single physical adapters for iSCSI traffic. Any thoughts?
You would never create a team and then put MPIO iSCSI directly on it. That’s true.
In this case, we’re making a switch team combo, then creating virtual NICs for MPIO. So, the stack is 2 MPIO vNICs, then a virtual switch, then a team, then the physical switch. It’s logically the same thing as two MPIO physical NICs direct to a physical switch which then hops through a LAG/port-channel to at least one more switch before reaching storage.
First of all… thank you for the excellent article. I’ve been intuiting this path for a while now to forego so many cables. We are moving to 40-100Gb connections for a 3 node cluster and new SSD SAN.
Can you mix frame sizes with this single team approach? Jumbo frames for ISCSI, or ISCI and Live Migration but standart 1500 MTU for all other virtual NICs and VLANs you create? Is there an advantage to jumbo frames with 10G, 25g, 40g 100g networking? …… and how where would you configure each one.
I assume the original NIC and possibly original team would need 9000 mtu settings?
You will get true MPIO with 2 virtual NICs spun off of the OS Team?
You can mix frame sizes, provided that no large frame ever tries to traverse a route that only accepts small frames. It won’t kill things, but it will force fragmentation.
Yes, two virtual NICs on top of a physical team will use real MPIO. It’s not quite as good as direct MPIO because the second abstraction layer might not make the same decisions. I doubt you’ll notice.