Save to My DOJO

Table of contents
As your organization grows it is important to not only plan your high-availability solution to maintain service continuity, but also a disaster recovery solution in the event that the operations of your entire datacenter are compromised. High-availability (HA) allows your applications or virtual machines (VMs) to stay online by moving them to other server nodes in your cluster. But what happens if your region experiences a power outage, hurricane or fire? What if your staff cannot safely access your datacenter? During times of crisis, your team will likely be focused on the well-being of their family or home, and not particularly interested in the availability of their company’s services. This is why it is important to not only protect against local crashes but to be able to move your workloads between datacenters or clouds, using disaster recovery (DR). Because you will need to have access to your data in both locations, you will need to make sure that the data is replicated and consistent in both locations. The architecture of your DR solution will influence the replication solution you select.
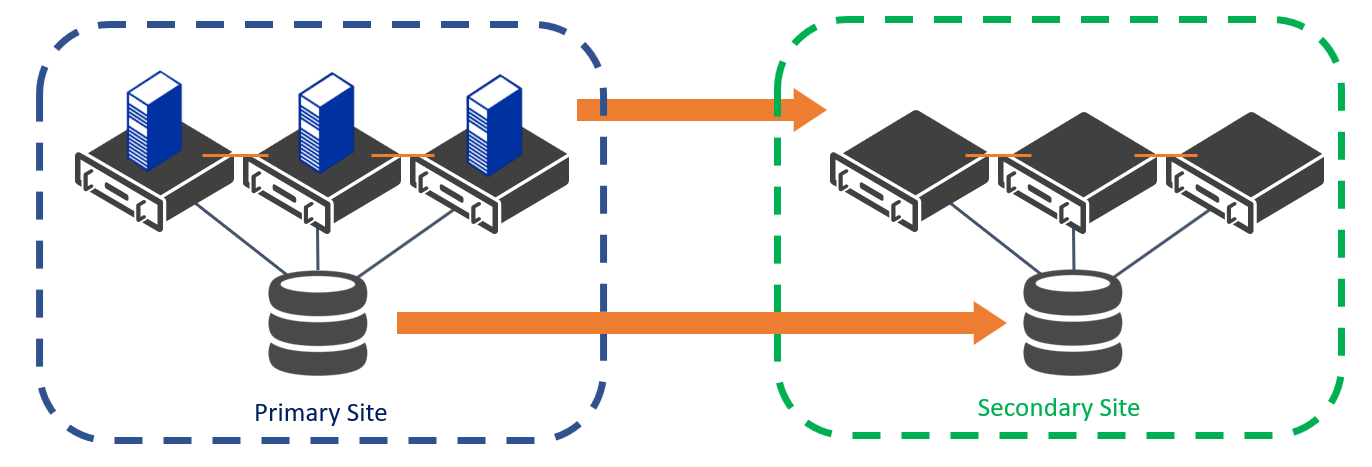
Basic Architecture of a Multi-Site Failover Cluster
This three-part blog post will first look at the design decisions to create a resilient multi-site infrastructure, then in future posts the different types of replicated storage you can use from third parties, along with Microsoft’s DFS-Replication, Hyper-V Replica, and Azure Site Recovery (ASR), and backup best practices for each.
Multi-Site Cluster Location Planning
Probably the first design decision will be the physical location of your second site. In some cases, this may be your organization’s second office location, and you will not have any input. Sometimes you will be able to select the datacenter of a service provider who allows cohosting. When you do have a choice, first consider the disaster between these locations. Make sure that the two sites are on separate power grids. Then consider what type of disasters your region is susceptible to, whether that is hurricanes, wildfires, earthquakes or even terrorist attacks. If your primary site is along a coastline, then consider finding an inland location. Ideally, you should select a location that is far enough away from your primary site to avoid multi-site failure. Some organizations even select a site that is hundreds or thousands of miles away!
At first, selecting a cross-country location may sound like the best solution, but with added distance comes added latency. If you wish to run different services from both sites (an active/active configuration), then be aware that the distance can cause performance issues as information needs to travel further across networks. If you decide to use synchronous replication, you may be limited to a few hundred miles or less to ensure that the data stays consistent. For this reason, many organizations choose an active/passive configuration where the datacenter which is closer to the business or its customers will function as the primary site, and the secondary datacenter remains dormant until it is needed. This solution is easier to manage, yet more expensive as you have duplicate hardware which is mostly unused. Some organizations will use a third (or more) site to provide greater resiliency, but this adds more complexity when it comes to backup, replication and cluster membership (quorum).
Multi-Site Cluster Node Planning
Now that you have picked your sites, you should determine the optimal number of cluster nodes in each location. You should always have at least two nodes at each site so that if a host crashes it can failover within the primary site before going to the DR site to minimize downtime. You can configure local failover first through the cluster’s Preferred Owner setting. The more nodes you have at each site, the more local failures you can sustain before moving to the secondary site.
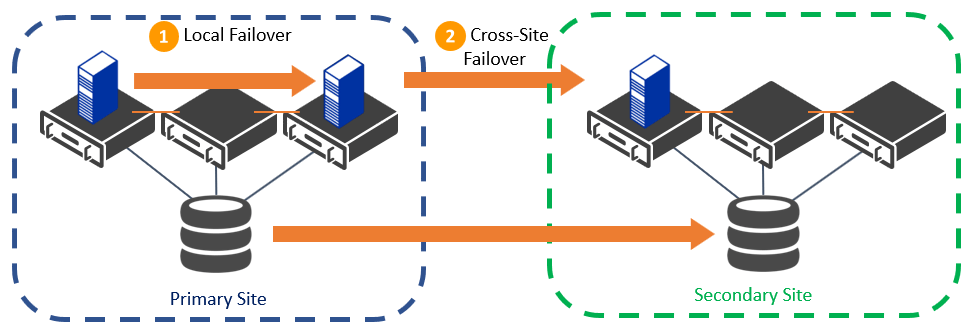
Use Local Failover First before Cross-Site Failover
It is also recommended that you have the same number of nodes at each site, ideally with identical hardware configurations. This means that the performance of applications should be fairly consistent in both locations and it should reduce your maintenance costs. Some organizations will allocate older hardware to their secondary site, which is still supported, but the workloads will be slower until they return to the primary site. With this type of configuration, you should also configure automatic failback so that the workloads are restored to the faster primary site once it is healthy.
If you have enough hardware, then a best practice is to deploy at least three nodes at each site so that if you lose a single node and have local failover there will be less of a performance impact. In the event that you lose one of your sites in a genuine disaster for an extended period of time, you can then evict all the nodes from that site, and still have a 3-node cluster running in a single site. In this scenario, having a minimum of three nodes is important so that you can sustain the loss of one node while keeping the rest of the cluster online by maintaining its quorum.
Multi-Site Cluster Quorum Planning
If you are an experienced cluster administrator, you probably identified the problem with having two sites with an identical number nodes – maintaining cluster quorum. Quorum is the cluster’s membership algorithm to ensure that there is exactly one owner of each clustered workload. This is used to avoid a “split-brain” scenario when there is a partition between two sets of cluster nodes (such as between two sites), and two hosts independently run the same application, causing data inconsistency during replication. Quorum works by giving each cluster node a vote, and a majority (51% or more) of voters must be in communication with each other to run all of the workloads. So how is this possible with the recommendation of two balanced sites with three nodes each (6 total votes)?
The most common solution is to have an extra vote in a third site (7 total votes). So long as either the primary or secondary site can communicate with that voter in the third site, that group of nodes will have a majority of votes and operate all the workloads. For those who do not have the luxury of the third site, Microsoft allows you to place this vote inside the Microsoft Azure cloud, using a Cloud Witness Disk. For a detailed understanding of this scenario, check out this Altaro blog about Understanding File Share Cloud Witness and Failover Clustering Quorum in the Microsoft Azure Cloud.
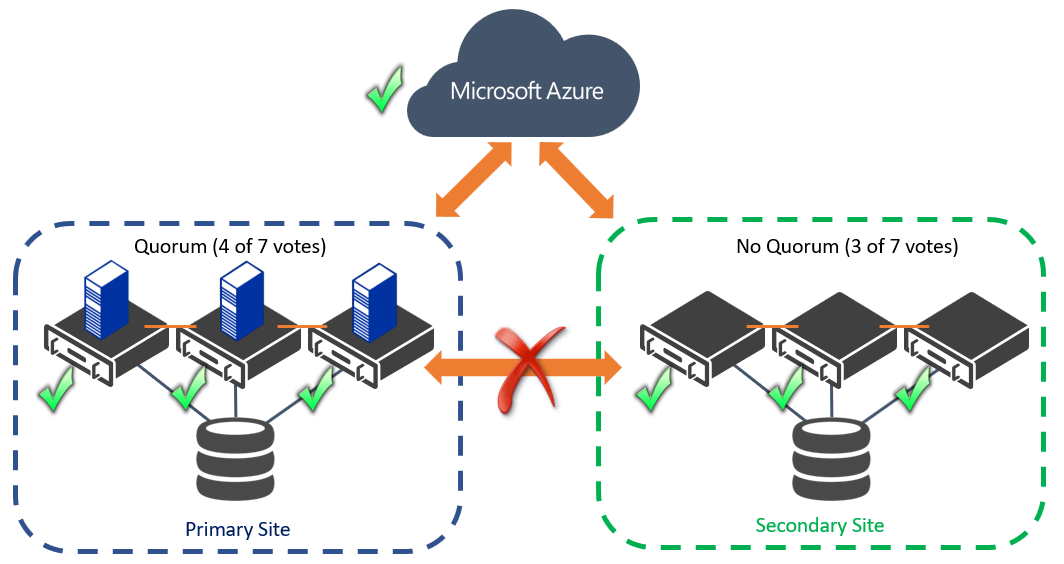
Use a File Share Cloud Witness to Maintain Quorum
Multi-Site Cluster Hardware Planning
If you are familiar with designing a traditional Windows Server Failover Cluster, you know that redundancy of every hardware and software component is critical to eliminate any single point of failure. With a disaster recovery solution, this concept is extended by also providing redundancy to your datacenters, including the servers, storage, and networks. Between each site, you should have multiple redundant networks for cross-site communications.
You will next configure your shared storage at each site cross-site replication between the disks using either a third-party replication solution such as Altaro VM Backup or Microsoft’s Hyper-V Replica or Azure Site Recovery. These configurations will be covered in the subsequent blog posts in this series. Finally make sure that the entire multi-site cluster, including the replicated storage, does not fail any of the Cluster Validation Wizard tests.
Wrap-Up
Again, we’ll be covering more regarding this topic in future blog posts, so keep an eye out for them! Additionally, have you worked through multi-site failover planning for a failover cluster before? What things went well? What were the troubles you ran into? We’d love to know in the comments section below!


Not a DOJO Member yet?
Join thousands of other IT pros and receive a weekly roundup email with the latest content & updates!
More in this category






About the Author
Symon Perriman

